Pwn入门阶段小结
一编:
意外看到这本书决定开始学到开始学,不到半小时;认认真真看到堆之前,用了半个月;回顾这本书,似乎填充了半年的快乐。
其实之前有学过小半个月的pwn尝试,ctfshow刷到54题(似乎)不知怎的,停下了就再也没有往后做。
从做题开始学,总感觉学的支离破碎;虽说看书本的话,似乎也只是知道一些理论知识。想着毕竟有一点点逆向和pwn那五十多道题基础,再看书,定是会有新的收获。
苦恼于书上的东西怎么搬到博客里,前几天看到 Jmp.Cliff 师傅直播,用自己的思考写最近他读的linux内核书。或许我也应该这样去做个小小的阶段性总结。
本想着读完这本书再写,卡到堆了。jc老师说最好去读glibc源码,看到老师博客里正好有一篇,提到前期基础要打好。这里也算是重新思考+总结这几天的学习成果。
同样感谢找到该书电子版的YuQ1ng队友👍(感恩,在他指导下做出了第一道栈迁移题目)
二编:
从头看之前在书上写的笔记,感觉,前后呼应颇多,也正好回答之前留下的一些问题——
三编:
最近软件安全课程的学习,发现对内容有了更多的丰富!打算加进来!!
四编: 搁置了好久(私密马赛(orz(12/10(这周必补完)
1. 二进制文件
1.1 从源码到可执行文件
1.1.1 编译原理
很好,又到了我们最爱的编译原理环节
编译器的作用是读入以某种语言(源语言)编写的程序,输出等价的另一种语言(目标语言)编写的程序。编译器结构可分为前端(Front end)和后端(Back end)两部分。前端是机器无关的,把我们写的源程序分解成组成要素和响应的语法结构,创建源程序的中间表示,收集和源程序相关的信息,存放到符号表;后端是机器相关的,根据中间表示和符号表信息构造目标程序。
以GCC编译阶段举例:
预处理–编译(词法分析–语法分析–语义分析–中间代码生成和优化–代码生成和优化)–汇编–链接
预处理:处理源代码中以“#”开始的预处理指令,转换后插入到程序中。
- 递归处理“#include”预处理指令,将对应文件的内容复制到该指令的位置
- 删除所有的“#define”指令,并且在其被应用的位置递归地展开所有的宏定义(或替换)
- 删除所有注释
- 添加行号和文件名标识
编译
TODO: 这里提一嘴 AT&T格式和intel格式:
TODO: cfi_* 汇编指示符
- 词法分析:
汇编
TODO:可重定向文件
重定位是链接符号定义与符号引用的过程。可重定位文件在构建可执行文件或目标文件时,需要把节中的符号引用换成这些符号在进程空间中的虚拟地址。
符号绑定和重定位攻击在后续的ret2dl-entries
汇编器根据汇编指令与机器指令对照表进行翻译,此生成的目标文件是可重定位文件
链接
包括地址和空间分配、符号绑定和重定位等操作。
1.2 ELF文件格式
TODO: 不是?看了这个wiki的ELF文件,讲的很详细,有时间读一遍。
扔一个
ELF分三种格式:
- 可执行文件(.exec)
- 可重定位文件(.rel)
- 共享目标文件(.dyn)
- *核心转储文件(core Dump file)
链接视角:
文件头(ELF header):存在魔术字符(确定映射地址)
节头表(section header table):
- 代码(.text):保存可执行的机器指令
- 数据(.data):保存已初始化的全局变量和局部静态变量
- BSS (.bss):保存未初始化的全局变量和局部静态变量(Block starting symbol)
- *.got: 全局偏移量表(全局变量引用的地址)
- *.got.plt:全局偏移量表(too),但是用于保存函数引用的地址
- .plt : 过程链接表,用于延迟绑定
segment和section的区别:
当我们在审视一个目标文件时,有两种视角可供参考,一是链接视角,通过节(section)来进行划分;另一种是运行视角,通过段(segment)来划分。
一段多节一段多节
运行视角看目标程序链接过程:
首先需要将该文件和动态链接库装在到进程空间中,形成一个进程镜像。
进程镜像中,仅仅包含各个段是不够的,还需要用到栈、堆、cDSO等空间,这些空间同样通过权限来进行访问控制,从而保证程序运行时的安全。
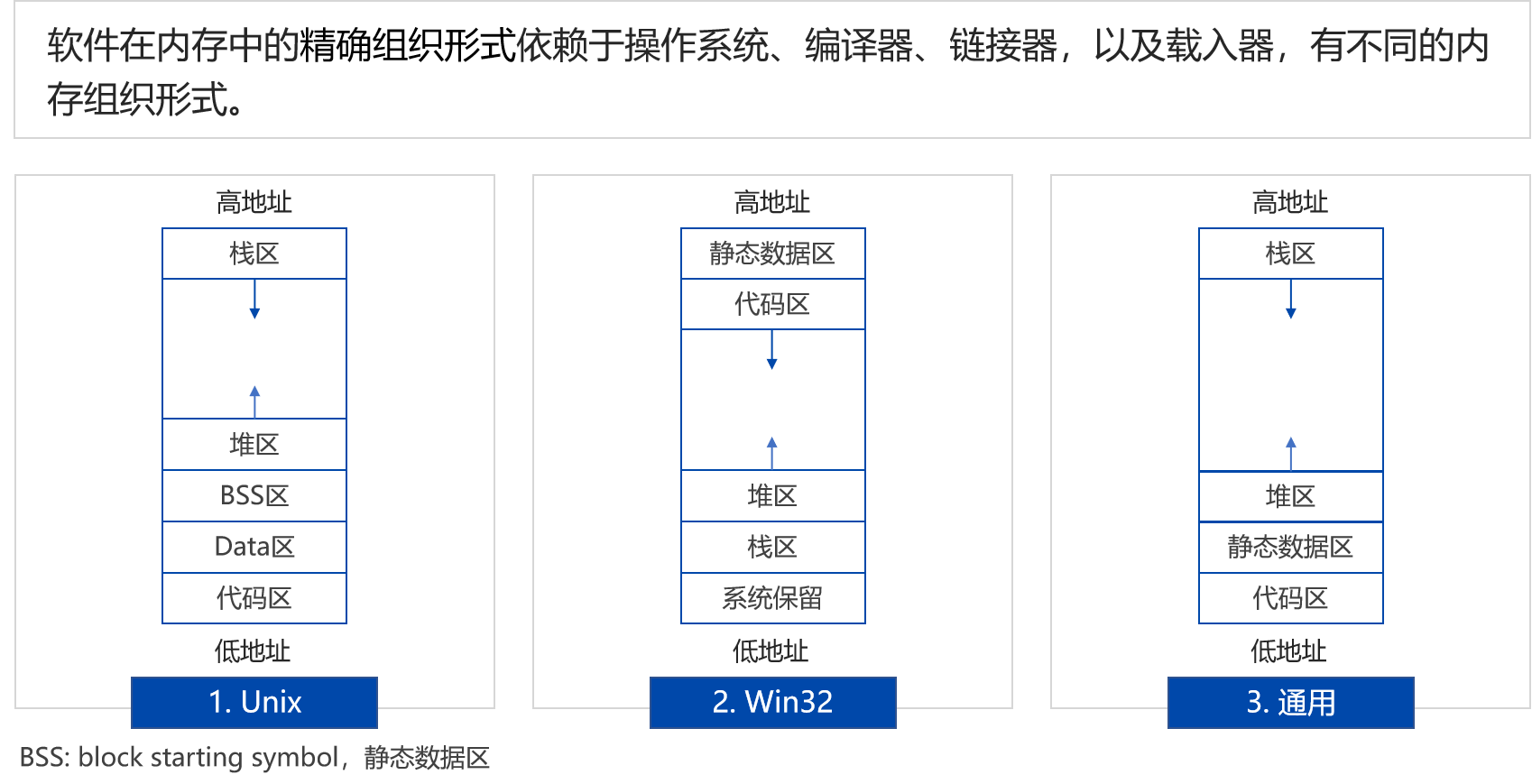

1.3 静态链接与动态链接
两个或者多个不同的目标文件是如何组成一个可执行文件的呢?这就需要进行链接(linking)。
- 编译时链接(compile time)
- 加载时链接(load time)
- 运行时链接(run time)
多文件链接方法:
- 按序叠加
- 相似节合并
静态链接在每一次调用位置都要装载一次代码,多个相同的库造成内存空间的浪费
为了引入RELRO保护机制,GOT被拆分为.got节和.got.plt节两个部分!不需要延迟绑定的前者用于保存全局变量引用,加载到内存后被标记为只读;需要延迟绑定的后者则用于保存函数引用,具有读写权限。
延迟绑定
ELF文件通过过程链接表(Procedure Linkage Table,PLT)和GOT配合来实现延迟绑定,每个被调用的库函数都有一组对应的PLT和GOT。
位于代码段.plt节的PLT是一个数组,每个条目占16字节。PLT[0]跳转动态链接器,PLT[1]调用系统启动函数__libc_start_main(),(main函数在此调用),PLT[2]开始就是被调用的各个函数条目。
位于数据段.got.plt节的GOT也是数组,每个条目占8字节。GOT[0]和GOT[1]包含动态连接器在解析函数地址时所需要的两个地址(.dynamic和relor条目),GOT[2]是动态连接器ld-linux.so的入口点,从GOT[3]开始,就是被调用的各个函数条目,这些条目默认只想对应PLT条目的第二条指令,完成绑定后次啊会被修改为函数的实际地址。
2. 汇编基础
2.1 CPU架构与指令集
指令集架构(Instruction Set Architecture,ISA)简称指令集,包含了一系列的操作码(opcode),以及由特定CPU执行的基本指令。指令集在CPU中的实现成为微架构,要想设计CPU,首先得决定使用是么阳得指令集,然后次啊是设计硬件电路。根据指令集得特征,通常分为CISC和RISC两大阵营。
处理器:指令集、寄存器、寻址方式
2.2 x86/x64汇编基础
CPU操作模式:
对于x86,主要的操作模式:保护模式、是地址模式和系统管理模式(此外还有一个保护模式的子模式,称为虚拟8086模式)




语法风格:
AT&T和Intel
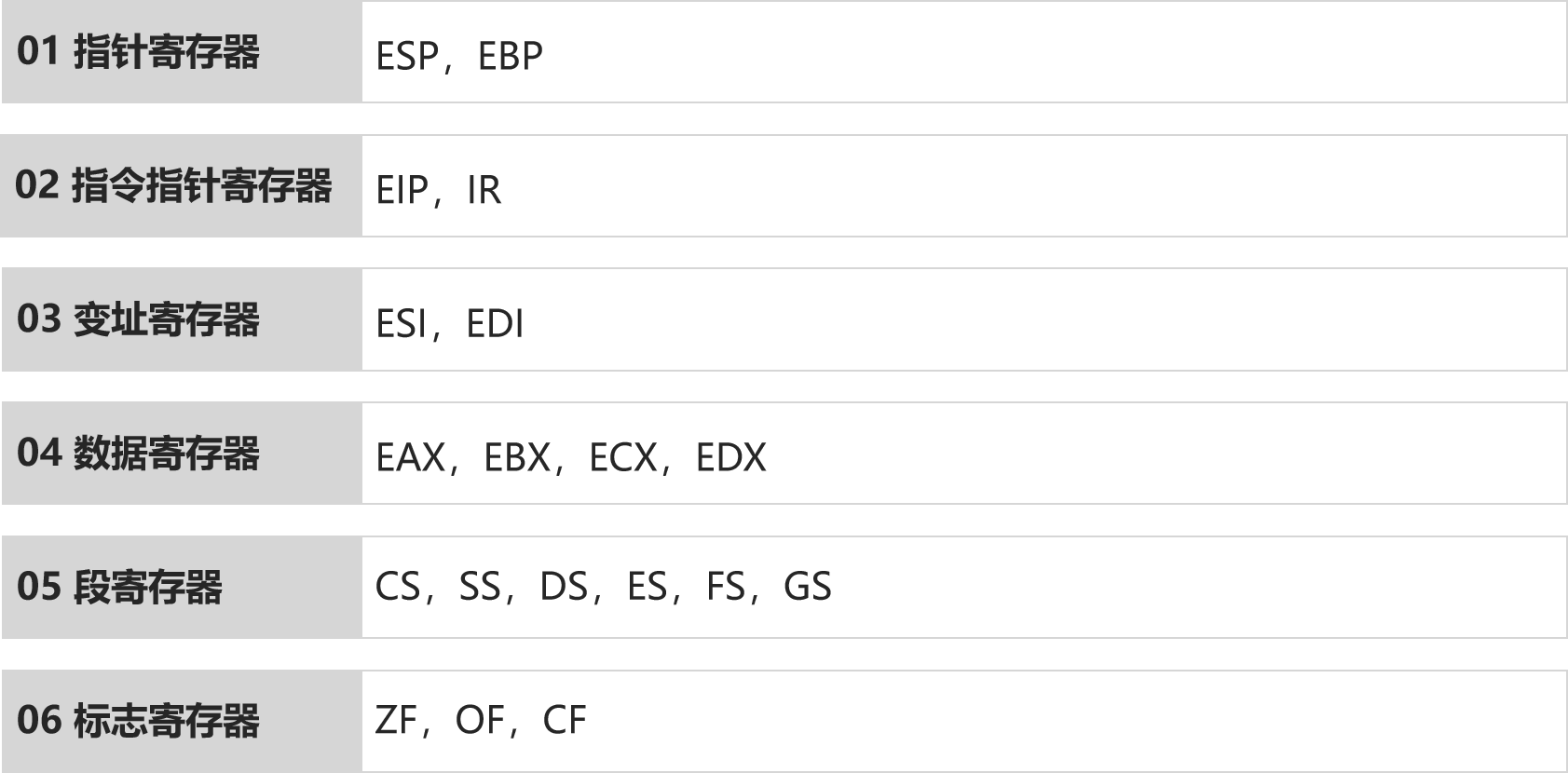
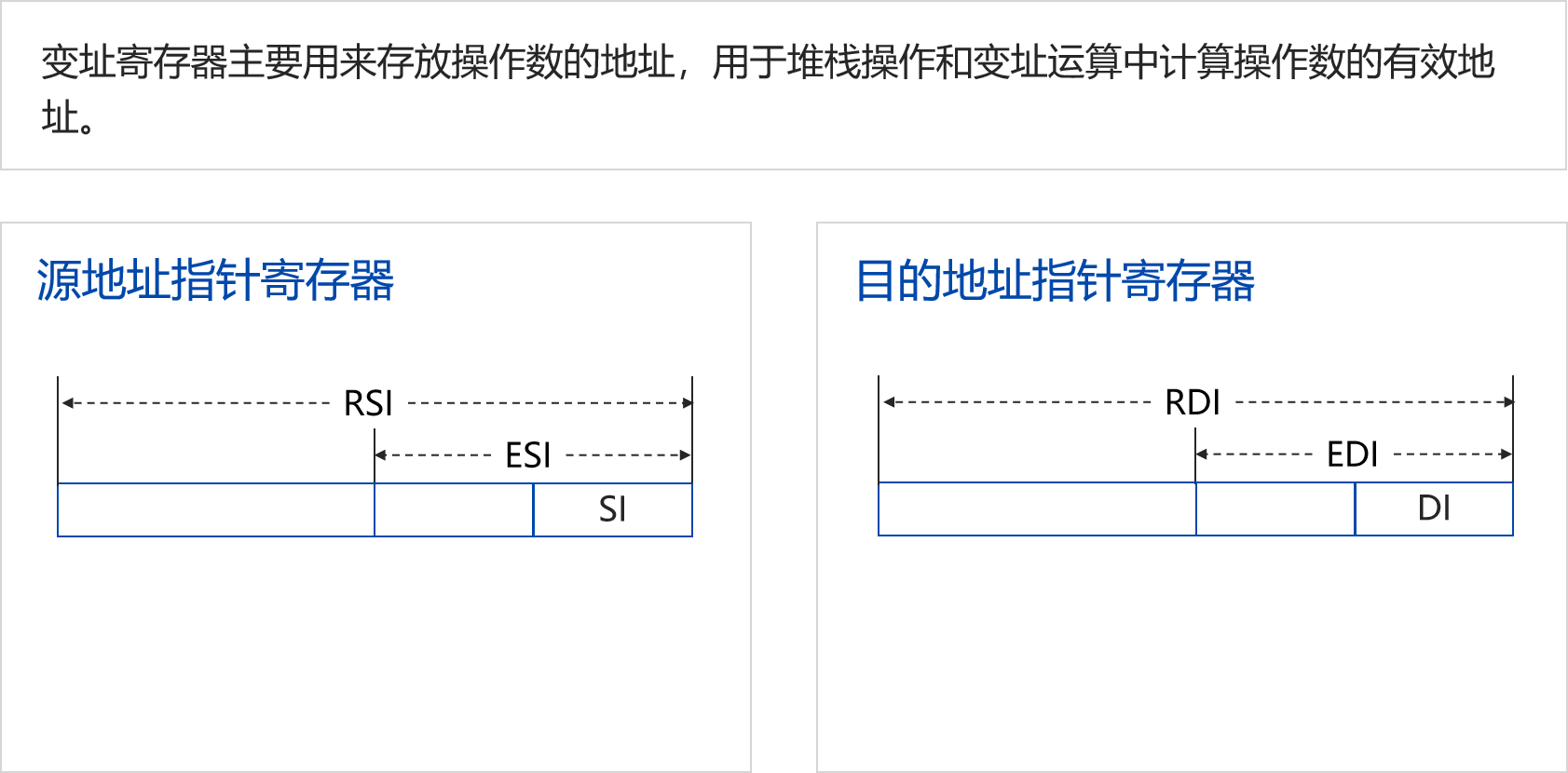
寄存器和数据类型:
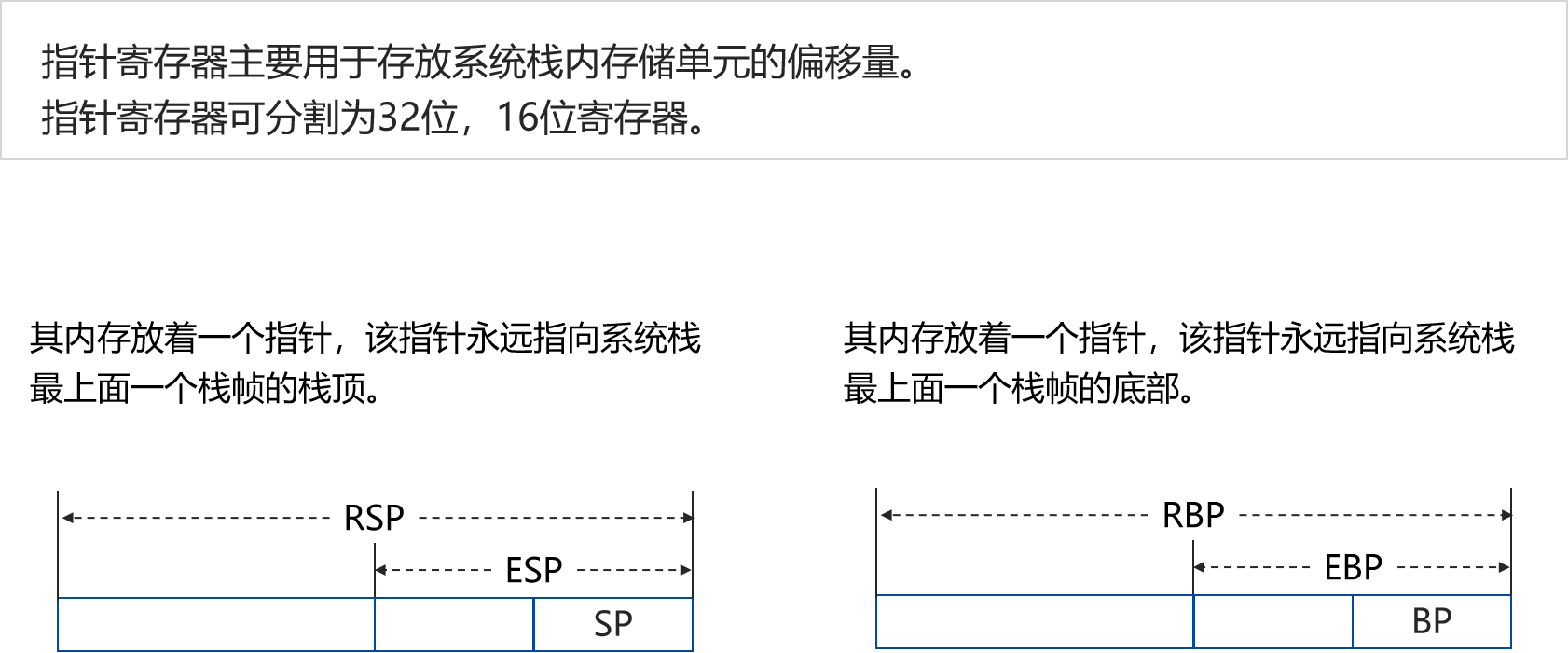
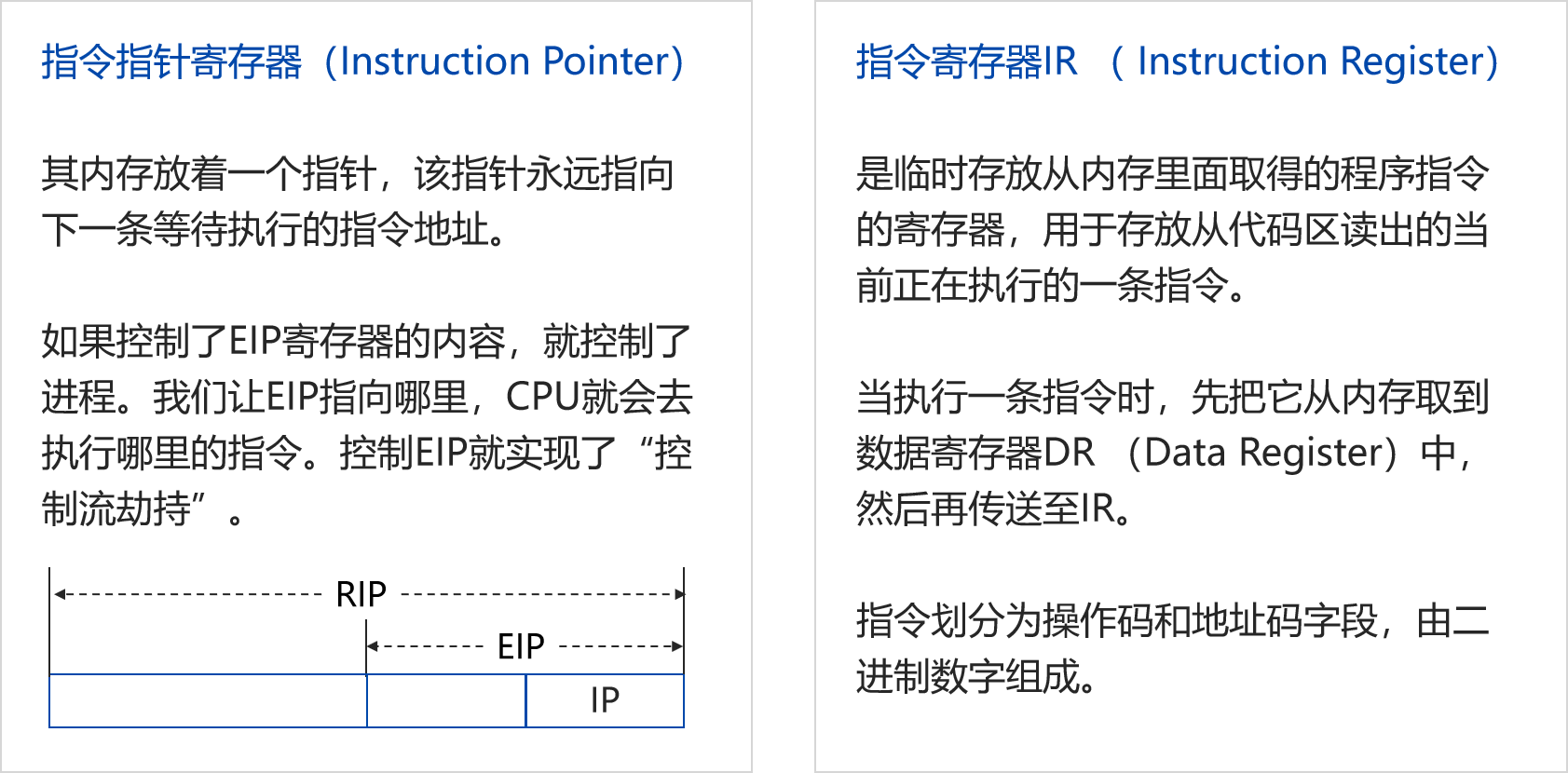
寄存器:
整数常量:
数据传送与访问
算术运算与逻辑运算
跳转指令与循环指令
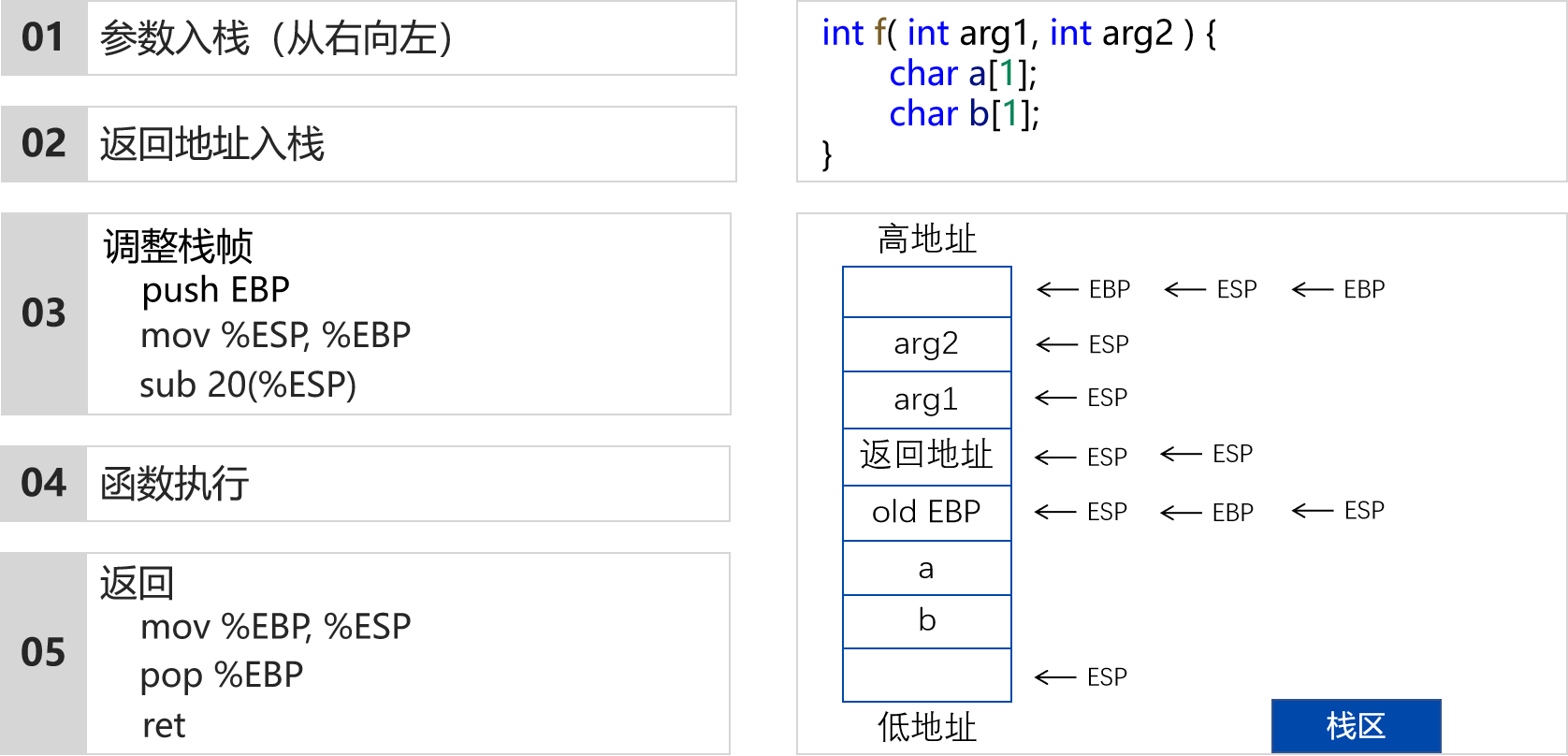
栈与函数调用


3. Linux安全机制
3.1 Linux基础
字节序:
eg:12345678
小端:
1 | > x/2w 0xffffd584 |
内核接口、用户接口
调用约定
3.2 Stack Canaries
3.3 No-eXecute
3.4 ASLR和PIE
3.5 FORTIFY_SOURCE
3.6 RELRO
4 整数安全
4.1整数溢出
定义
整数溢出一般有三个情况
- 溢出:有符号数会发生溢出,有符号数的最高位标识符号,在两正或两负相加时,有可能改变符号位的值,产生溢出;此时OF标志位可能显示溢出
- 回绕:无符号数0-1时会变成最大的数,;此时标志位CF可能显示回绕
- 截断:将一个较大宽度的数存入一个宽度较小的操作数中,存在高位截断
漏洞多发函数
<经常配合其他类型的缺陷才能有用>
size_t类型的参数(size_t时无符号整数类型sizeof()的结果)
memcpy()函数将src所指向的字符串中以ssrc地址开始的前n个字节复制到dest所指向的数组中,并返回dest;
1 |
|
strncpy()函数从源src所指的内存地址的起始位置开始复制n个字节到目标dest所指的内存地址的起始位置中;
1 |
|
两个函数中都有类型为size_t的参数,它是无符号整型的sizeof运算符的结果
1 | typedef unsigned int size_t; |
来点例题:
整数转换
1 | char[80]; |
类似例题:
[BJDCTF 2020]babystack2.0
回绕和溢出
1 | void vulnerable(){ |
类似例题:
来自作业里的一道题:
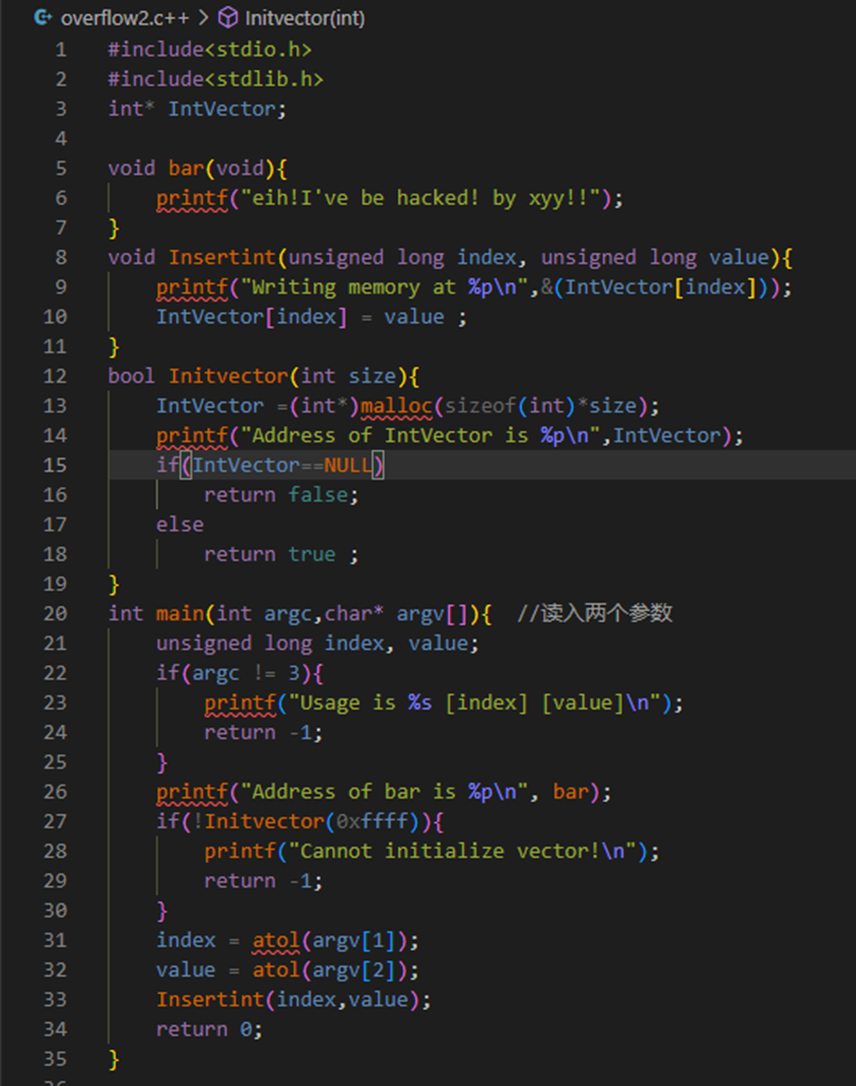
atol() 常用于将用户输入的字符串或命令行参数(通常是字符串)转换为 long 类型的数值,以便进行后续的计算或处理。
先看可能会出现的问题:
- Insertint函数的数组越界:在堆中,index超过了分配大小,数组越界,进而引发未定义行为(UB)
一道堆溢出,而且告知了利用的bar函数位置,没有任何保护(一定要在winXP中),
选择0x12ff84作为第一个参数:栈的返回值的地址为 0x12FF84
计算偏移:
$$
参考数组元素地址 = 数组基址+下标*数组元素大小
$$
- 要想覆盖到 0x0012FF84,必须要使前两位溢出才可以。因此列出算式:
0x410048 + index * 4 = 0x10012FF84
解得 index = 1072988111,bar 的地址转为十进制即 4198400
利用漏洞执行 bar()函数成功:
另一道:
1 |
|
截断
1 | void main(int argc, char *argv[]){ |
例题:
还没找到(?
5 格式化字符串
5.1 格式化输出函数
5.2 格式化字符串漏洞
6 栈溢出与ROP
6.1 栈溢出原理
6.2 ROP
6.3 Blink ROP
6.4 SROP
6.5 stack pivoting
6.6 red2dl-resolve
7 堆
7.1 堆的内存组织
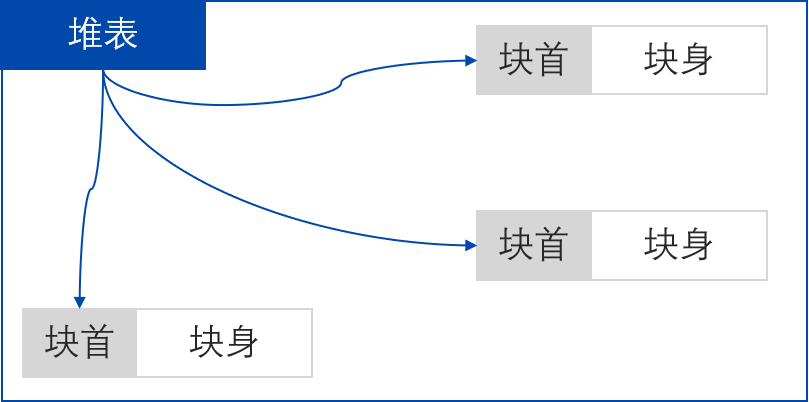
堆表:一般位于整个堆区的开始位置,用于索引队去中所有堆块的重要信息,包括腿快的位置、腿快大小、空闲还是占用等;在设计时,可能会采用平衡二叉树等高校数据结构用于优化查找效率。现代操作系统的堆表往往不止一种数据结构;在Windows系统中,占有态的堆块被使用它的程序索引,堆表只索引所有空闲态的堆块。
堆块:是堆的基本组织单位,包括块首和块身两个部分。块首标识堆块自身信息;堆身紧随其后,是最终分配给用于使用的数据区。
堆块指针:指向堆块的指针或者句柄,指向的是块身的首地址,也就是,我们使用函数申请得到的地址指针都会越过8字节(32位系统)的块首,直接指向数据区(块身)。
堆块大小:堆块的大小包括块首在内,如果申请32字节,实际会分配40字节,即8字节的块首+32字节的块身。堆块的单位是8字节,不足8字节按8字节分配。

堆表有两种常见的结构:
- 空闲双向链表Freelist(简称空表)
- 快速单向链表Lookaside(简称快表)
其中快表一般难以被利用,故不作详述。
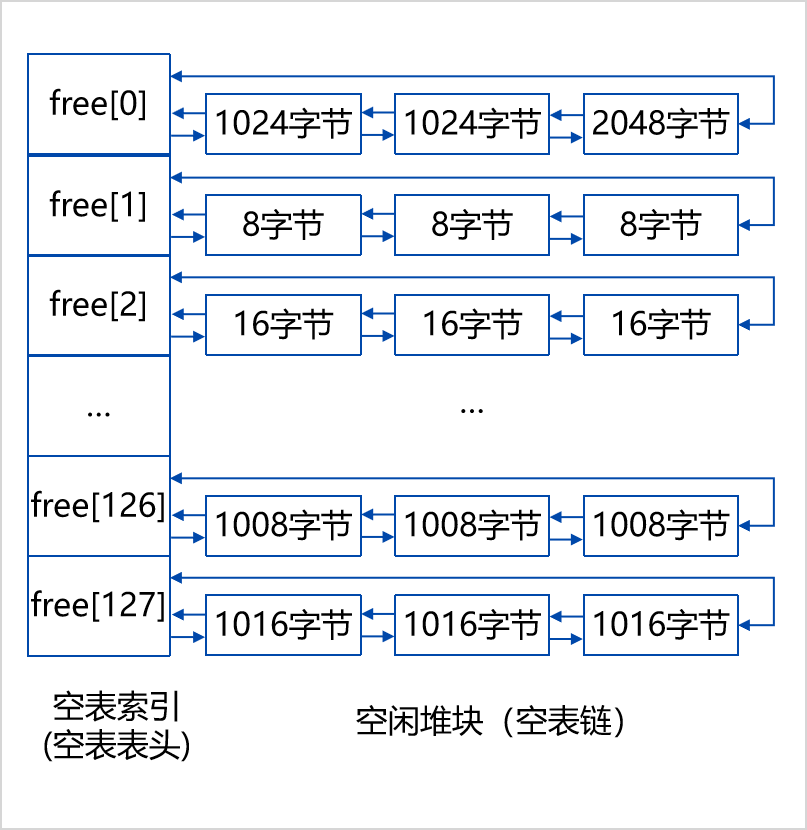
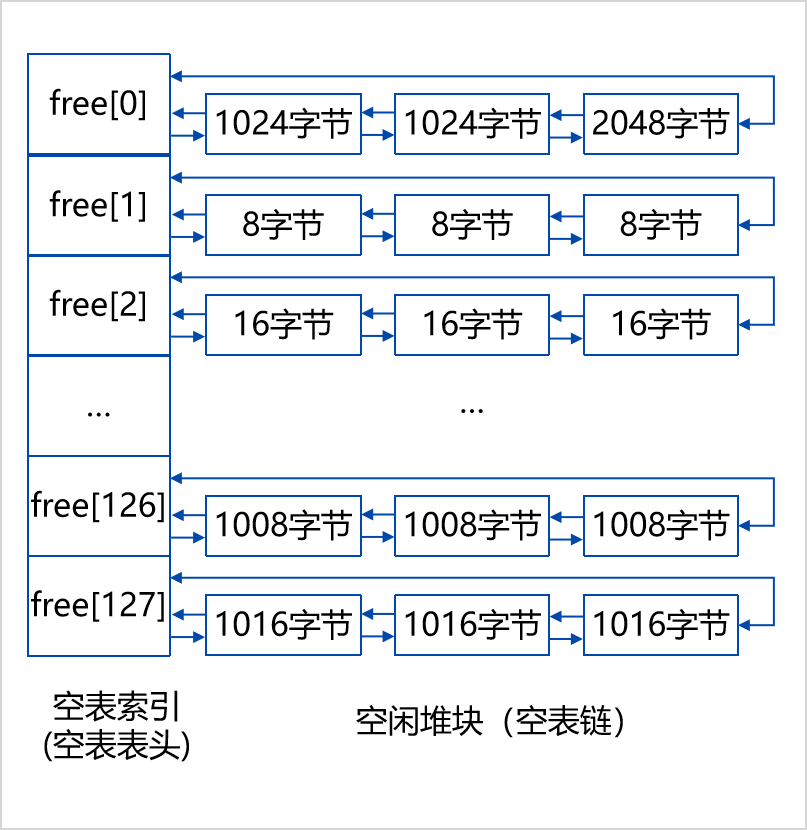
空表包含空表索引和空闲堆块两个部分,
空表索引也叫空表表头,是一个大小为128的指针数组,该数组的每一项包括两个指针,用于标识一条空表。 (如图左一列
空表索引的第一项free[0]所标识的空表相对比较特殊,这条双向链表链入了所有大于或等于1024字节小于512KB的堆块,升序排列。这个空表通常又称为零号空表。
空表索引的第二项(free[1])标识了堆中所有大小为8字节的空闲堆块。
之后每个索引项指示的空闲堆块递增8字节。例如, free[2]为16字节的空闲堆块, free[3]为 24 字节的空闲堆块。
依据既定的查找空闲堆块的策略,找到合适的空闲堆块之后,将其状态修改为占用态、把它从堆表中“卸下”、返回一个指向堆块块身的指针给程序使用。
普通空表分配时首先寻找最优的空闲块分配,若失败,一个稍大些的块会被用于分配。这种次优分配发生时,会先从大块中按请求的大小精确地“割”出一块进行分配,然后给剩下的部分重新标注块首,链入空表。也就是说,空表分配存在找零钱的情况。
零号空表中按照大小升序链着大小不同的空闲块,故在分配时先从free[0]反向查找最后一个块(即最大块),看能否满足要求,如果满足要求,再正向搜索最小能满足要求的空闲堆块进行分配。
eg:
对于如下代码:
2
char * p2 = new char[30];我们可以从以下几个方面来解释“为何分配到堆”和“为何不可确认
p1和p2的大小”:1. 为何分配到堆?
代码中的
new操作符用于动态分配内存。默认情况下,new操作符会在堆中分配指定大小的内存空间。因此:
int* p1 = new int[200];会在堆上分配 200 个int类型的空间。char* p2 = new char[30];会在堆上分配 30 个char类型的空间。堆内存分配可以在运行时根据需求动态分配和释放,与栈不同的是,栈的内存分配是在编译时就确定的,并在函数作用域结束时自动回收。
2. 为何不可确认
p1和p2的大小?指针变量
p1和p2是指向内存地址的指针,并没有记录数组的大小信息,因此仅通过指针变量本身无法得知所指向的内存块的大小。即:
p1的类型是int*,只是一个指向int类型数组的指针,指针变量中存储的是堆上分配的数组首地址,而数组的长度信息(200)并没有保存在指针本身中。p2的类型是char*,同样也只记录了指向char类型数组的首地址,而new char[30]分配的 30 字节大小信息也没有包含在p2中。这种情况下,如果需要得知堆上分配的数组大小,就必须额外记录或传递数组的长度(如使用变量保存长度,或封装到
std::vector等容器中)。总结
- 堆分配:
new操作符动态分配的内存默认分配在堆上。- 大小不可知:指针
p1和p2本身不包含长度信息,因此无法直接从指针推断出堆中分配的内存块大小。

