很好,刚想起来后天早八寄网期末考
以下题目都在 TJU-CourseSharing/2440130_计算机网络 at main · superpung/TJU-CourseSharing · GitHub
学期中有把计网书过了一遍(水过地皮湿(希望吧…
说着不想复习不想复习,半夜00:16从床上坐起来突然就想复习了,复习到4点把重点全过了一遍 (p人是这样的)
感谢期中看过的地皮和这学期的网络协议选修(orz
请先往后翻看2022年的题目,因为题目比较详细,所以先写的那份
希望对之后复习这部分的学弟学妹们有些帮助,有问题随时提出 飞快地改!
2019 级考试内容:
选择题(每题 2 分):
- 数据包交换
- 网络延迟
- P2P 架构
- 链路层可靠数据传输
- HTTP
- 可靠传输
- TCP
- 路由协议
- CSMA/CA
- ARP
CSMA/CD 原理、二进制指数退避算法(5 分)
- 适配器从网络层一条获得数据报,准备链路层帧,并将其放入帧适配器缓存中。
- 如果适配器侦听到信道空闲(即无信号能量从信道进入适配器),它开始传输帧。
在另一方面,如果适配器侦听到信道正在忙,它将等待,直到侦听到没有信号能量时才开 始传输帧。
在传输过程中,适配器监视来自其他使用该广播信道的适配器的信号能量的存在。
如果适配器传输整个帧而未检测到来自其他适配器的信号能量,该适配器就完成 了该帧。
在另一方面,如果适配器在传输时检测到来自其他适配器的信号能量,它中止传输(即它停止了传输帧)。
- 中止传输后,适配器等待一个随机时间量,然后返回步骤2。
选择随机时间量机制叫二进制指数后退,即在经历n次碰撞后,从0…<2^n-1中选择一个数
令d_{prop}为信号能量在任意两个适配器之间传播所需的最大时间,令d_{trans}为传输一个最大长度的以太网帧的时间,我们有CSMA/CD的效率公式如下
$$
\frac 1 {1 + 5d_{prop}/d_{trans}}
$$
TCP 报文段 ACK 序列号(4 分)
?这是在问啥?
放个TCP连接建立
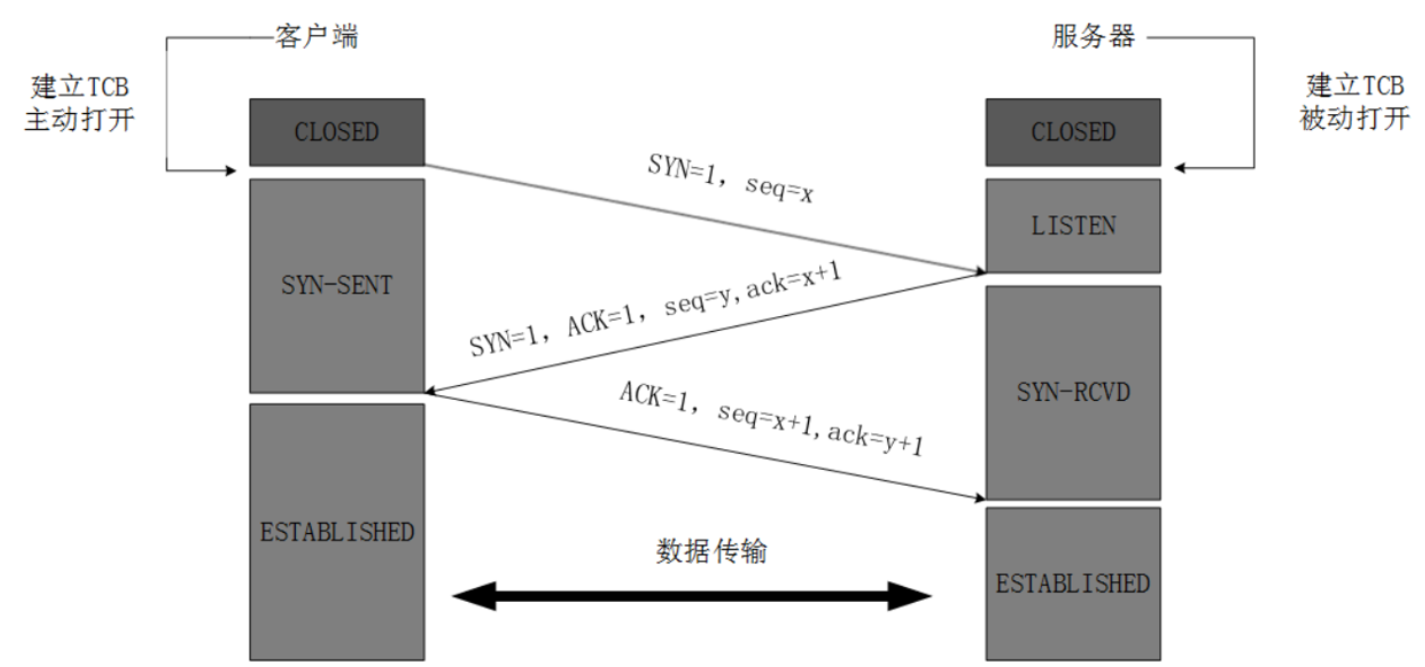
Internet 访问外网 Web 协议顺序及功能(15 分)

网络拓扑 Dijkstra 算法填表(12 分)
后面有
HTTP 持续/非持续(10 分)
发起一个TCP连接时,创建一个套接字,发送请求报文,获取响应报文,关闭TCP,检索响应报文中的HTML文件,发送有10个图片的引用,于是对每个图片重复发起TCP连接的过程,这是一个非持续连接。
这里我们可以了解到RTT,为往返时间,包括分组传播时延、分组在中间路由器和交换机上的排队时延和分组处理时延。
如果使用非持续连接,每次请求一个文件至少有两个RTT,对服务器带来眼中的负担。
持续连接
如果打开网页后保持一个TCP连接,可以在一个浏览过程中减少近一倍RTT的时间。
子网划分(12 分)
非常好的题,拿来!
TCP Reno 拥塞控制的图象(10 分)
好学,自己学。(下面有)
交换机自学习即插即用与 ARP 即插即用的工作方式和异同(12 分)
一、交换机自学习即插即用的工作方式
自学习是交换机实现即插即用的重要特性,它依赖于MAC 地址表,实现局域网(LAN)内的数据转发。
- 基本工作过程
- 初始状态:交换机的 MAC 地址表为空。
- 接收帧:当交换机收到一个数据帧时,会读取帧的 源 MAC 地址 和入接口。
- 学习:交换机会将源 MAC 地址和对应的入接口记录到 MAC 地址表中。
- 转发帧
- 如果目标 MAC 地址已在表中,交换机将数据帧转发到对应的接口。
- 如果目标 MAC 地址不在表中,交换机会将数据帧泛洪(Flooding)到所有接口(除接收数据的接口)。
- 动态更新:MAC 地址表是动态的,老化时间过后,未更新的条目会被删除。
总结:交换机通过自学习不断更新 MAC 地址表,从而实现数据的高效转发。
二、ARP 即插即用的工作方式
ARP(Address Resolution Protocol) 是 IP 网络中用于解析 IP 地址到 MAC 地址的协议,帮助设备即插即用地进行通信。
- 基本工作过程
- ARP 请求
- 当主机 A 需要发送数据到某个 IP 地址(例如主机 B)时,A 先检查自己的 ARP 缓存表。
- 如果找不到对应的 MAC 地址,A 会发送一个广播的 ARP 请求帧,询问 “谁是 IP 地址 X.X.X.X,请告诉我你的 MAC 地址”。
- ARP 回复
- 目标主机(如主机 B)接收到 ARP 请求后,会回复一个单播的 ARP 响应,告知 A 自己的 MAC 地址。
- 缓存学习
- 主机 A 收到 ARP 响应后,将 IP 地址与 MAC 地址的对应关系记录到 ARP 缓存表 中。
- 动态更新
- ARP 缓存表具有老化机制,如果一段时间未使用,条目会被删除。
- ARP 请求
总结:ARP 协议通过地址解析,实现 IP 地址到 MAC 地址的映射,进而支持网络设备即插即用地通信。
三、交换机自学习与 ARP 即插即用的异同
| 比较项 | 交换机自学习 | ARP 即插即用 |
|---|---|---|
| 目的 | 维护 MAC 地址表,实现帧的高效转发 | 解析 IP 地址到 MAC 地址,实现网络通信 |
| 工作层次 | 数据链路层(第二层) | 网络层(第三层) |
| 触发方式 | 数据帧到达交换机 | 主机需要解析未知的 IP 地址 |
| 学习内容 | MAC 地址与交换机端口的对应关系 | IP 地址与 MAC 地址的对应关系 |
| 通信方式 | 使用交换机的端口学习,进行帧的泛洪 | 发送 ARP 广播请求,接收单播响应 |
| 表结构 | MAC 地址表 | ARP 缓存表 |
| 动态更新机制 | 自动学习,老化未使用的条目 | 自动学习,老化未使用的条目 |
四、总结
- 相同点:
- 都具有即插即用的特性,自动学习网络地址映射关系。
- 都具有老化机制,动态删除长时间未使用的条目。
- 都是网络设备实现高效通信的重要机制。
- 不同点:
- 交换机自学习工作在数据链路层(L2),维护的是MAC 地址表。
- ARP 即插即用工作在网络层(L3),维护的是IP 地址与 MAC 地址的映射关系。
交换机自学习主要用于数据帧转发,而 ARP 协议用于 IP 数据包的地址解析,两者结合可以实现数据链路层和网络层的无缝通信。
2021级
选择
关于网络应用(network application)和应用层协议(network application-layer protocol),下列说法正确的是()
A.应用层协议的性能对网络应用的性能没有影响,
B.应用层协议负责数据传输。
C.网络应用就是应用层协议,二者没有区别。
D.应用层协议的设计包括用户界面的设计。
关于网络延迟,下列说法正确的是()
A.排队延迟(queueing delay)和网络中业务量的变化无关
B.传输延迟(transmission delay)和两个节点的物理距离有关。距离越大,传输延迟越大。
C.传播延迟(propagation delay)和链路的带宽有关。带宽越大,传播延迟越小。
D.节点处理延迟(nodal processing delay) 通常很短,可以忽略不计。
CD反了
关于数据包交换(packet switching),下列说法正确的是()
A.传输过程中没有丢包和乱序,
B.发送数据前要建立连接。
C.中间节点不需要要存储-转发(store-forward)数据包
D.每个数据包独立寻路。
节点A和B间有条微波无线链路相连。A和B相距100Km,带宽为30 Kbps,数据包长度为1000 bits。需要在A和B间实现可靠数据传输,下列说法正确的是(
A. 使用停-等(stop-and-wait)可靠传输协议就能获得很高的链路利用率,
B.不需要采用任何可靠传输协议就能实现可靠传输。
C.使用FEC(Forward Error Correction)不能改善这条链路的可靠数据传输性能
D.只有使用并行的(pipelined)可靠传输协议才能获得较高的链路利用率。
题目解析
要解答该问题,我们需要考虑链路的基本特性、数据传输协议的性能以及链路利用率的计算。
背景信息:
节点 A 和 B 之间的链路参数:
- 距离:d=100 Km=
- 带宽:B=30 Kbps=
- 数据包长度:L=1000 bits=
传播时延(Propagation Delay): 假设信号传播速率 v≈2×10^8 m/s(光速在空气中)。
$$
\text{传播时延} = \frac{\text{距离}}{\text{信号传播速率}} = \frac{100 \times 10^3}{2 \times 10^8} = 0.5 , \text{ms}
$$传输时延(Transmission Delay): 传输时延是发送数据所需的时间,计算公式为:
$$
\text{传输时延} = \frac{\text{数据包长度}}{\text{链路带宽}} = \frac{1000 , \text{bits}}{30 \times 10^3 , \text{bits/s}} = 0.0333 , \text{s} = 33.3 , \text{ms}
$$A. 使用停-等(Stop-and-Wait)协议就能获得很高的链路利用率
*停-等协议的特点**:发送方发送一个数据包后,必须等待接收方确认(ACK)才能发送下一个数据包。
链路利用率的计算公式为:
链路利用率=传输时延传输时延+2×传播时延\text{链路利用率} = \frac{\text{传输时延}}{\text{传输时延} + 2 \times \text{传播时延}}
代入数值:
- 传输时延:33.3 ms
- 传播时延:0.5 ms
$$
\text{链路利用率} = \frac{33.3}{33.3 + 2 \times 0.5} = \frac{33.3}{34.3} \approx 97%
$$分析:虽然停-等协议在短距离高带宽链路中利用率较低,但在此链路中,传输时延远大于传播时延,因此利用率较高。
选项 A 是正确的。
B. 不需要采用任何可靠传输协议就能实现可靠传输
无线链路通常存在干扰、误码率高等问题,数据传输可能会出现丢包或错误。
因此,为了实现可靠传输,必须采用某种可靠传输协议(如停-等协议、滑动窗口协议等)。
选项 B 是错误的。
C. 使用 FEC(前向纠错)不能改善这条链路的可靠数据传输性能
FEC(Forward Error Correction)是一种在传输时加入冗余信息的技术,可以在接收方检测并纠正部分错误,减少重传需求。
在无线链路中,FEC 可以有效减少传输错误,从而提高可靠传输的性能。
选项 C 是错误的。
D. 只有使用并行的(Pipelined)可靠传输协议才能获得较高的链路利用率**
并行可靠传输协议(如滑动窗口协议)可以在等待 ACK 的同时继续发送多个数据包,从而提高链路利用率。
然而,在本链路中,由于停-等协议已经可以实现较高的利用率(97%),不一定需要并行协议才能达到高利用率。
选项 D 是错误的。
关于HTTP,下列说法正确的是()
A. HTTP 的数据包头部是以二进制形式存储的,很难读懂内容。
B.使用UDP协议。
C.HTTP 服务器采用无状态(stateless)管理方式,不保存客户端的任何状态信息。为了能记录用户状态,需要使用cookies。
D. HTTP的web proxy 总是能够降低响应时间,提升用户体验。
关于可靠数据传输,下列说法正确的是()
A. SR协议中,发送端窗口通常和接收端窗口大小相等,并且大于等于数据包最大序列号的一半.。
在 SR(Selective Repeat)协议 中,发送方和接收方窗口的大小是有限的,但通常满足以下条件:
窗口大小≤序列号空间大小2
$$
\text{窗口大小} \leq \frac{\text{序列号空间大小}}{2}
$$
- 这里的序列号空间是数据包序列号的最大值加 1。
- 这是为了避免序列号混淆,因为 SR 协议允许接收方接收和缓存不按顺序到达的数据包。
因此,发送窗口和接收窗口的大小不一定 相等,且必须小于数据包最大序列号的一半。
B.SR(Selective Repeat)和GBN都采用滑动窗口(sliding window)机制实现对发送端/接收端缓冲区的管理。
SR 和 GBN 协议 都属于滑动窗口协议。
- GBN(Go-Back-N)
- 发送方维护一个连续的滑动窗口。
- 接收方只接收按顺序到达的数据包,丢弃失序的数据包。
- SR(Selective Repeat)
- 发送方和接收方都维护滑动窗口。
- 接收方可以接受不按顺序到达的数据包,并缓存起来。
C.停-等(stop-and-wait)协议的链路利用率一定低于GBN(Go-Back-N)。
链路利用率计算公式:
$$
\text{利用率} = \frac{\text{传输时延}}{\text{传输时延} + 2 \times \text{传播时延}}
$$
D.在停-等协议中,数据包(data)丢失引发的超时重传会导致接收端收到重复的数据包,
下列哪些协议层是在操作系统的用户空间实现的?
A. 应用层
B.传输层
C.网络层
D. 物理层
E.数据链路层!
关于网络层,下列说法正确的是()
A.路由器(router)和交换机(switch)都是网络层的互联设备。
B.网络层的数据平面(data plane)负责转发(forwarding),控制平面(control plane)负责路由(routing)。
C.IP协议维护转发表(forwarding table)。
D.不同物理介质(physica media)的网络如果要互联(internetworking),那么在网络层也可以使用不同的IP协议。
关于路由算法,下列说法正确的是()
A.路由算法负责为数据包从源节点到目的节点找到一条性能好的路径。因此必须知道全局的网络拓扑结构。
B.跳数(the number of hops)不能做为路由算法的性能评价参数。
C.路由算法的性能评价参数必须根据设计需求来确定。
D.路由算法的性能对网络性能影响不大!
关于TCP的流量控制(flow control),下列说法正确的是()
A.不能减少丢包的发生,
B.和网络传输速率有关。
C.不能改变发送端的发送速率。
D.为了解决TCP两端发送速率和接收速率不匹配的问题
大题
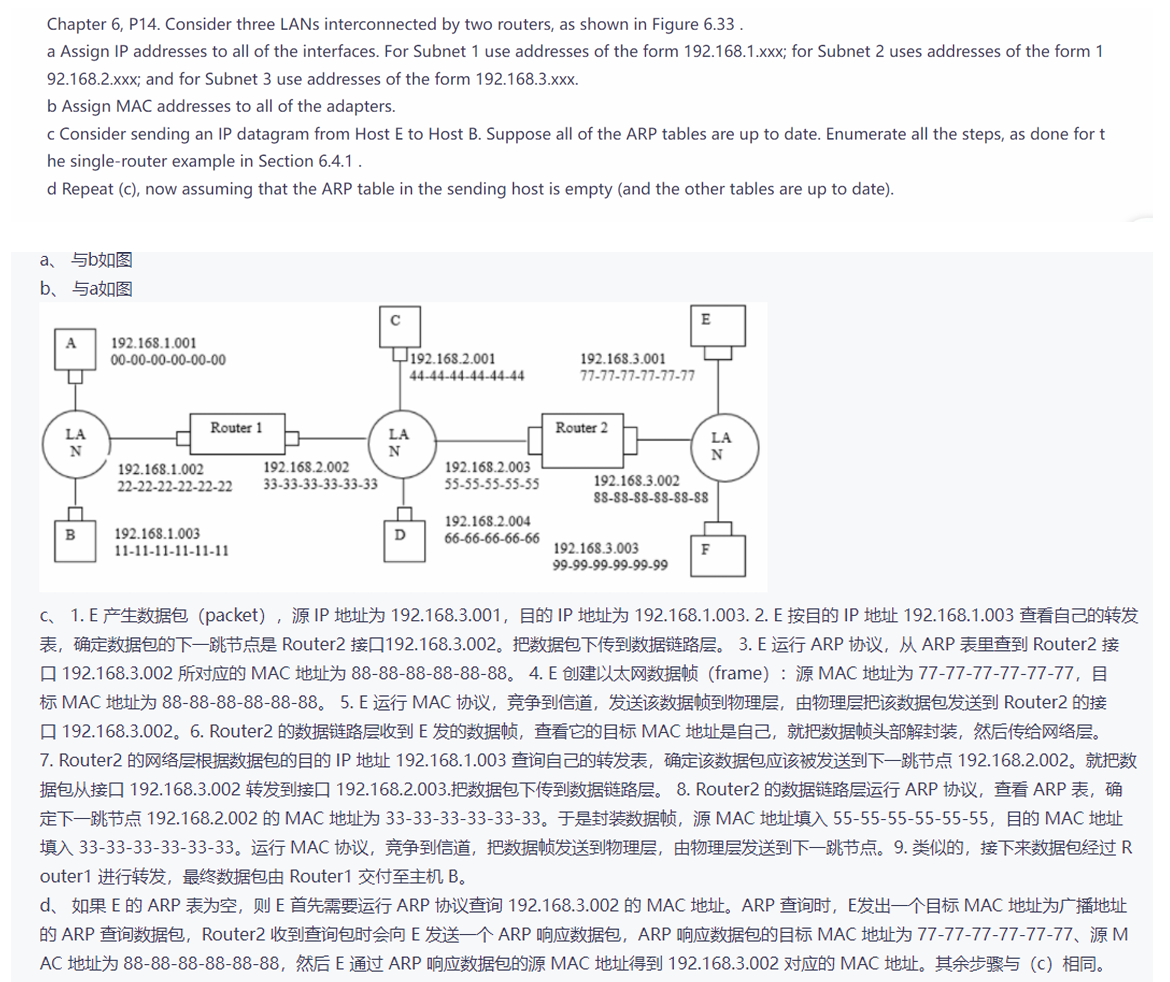
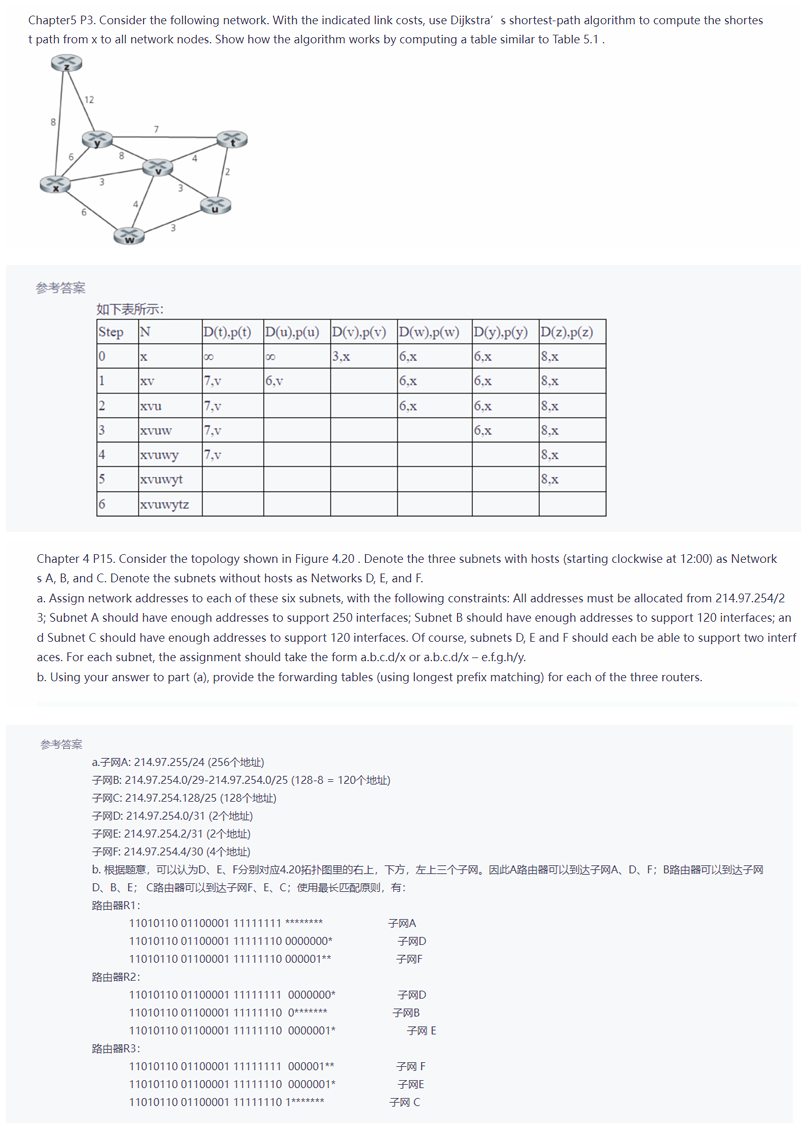
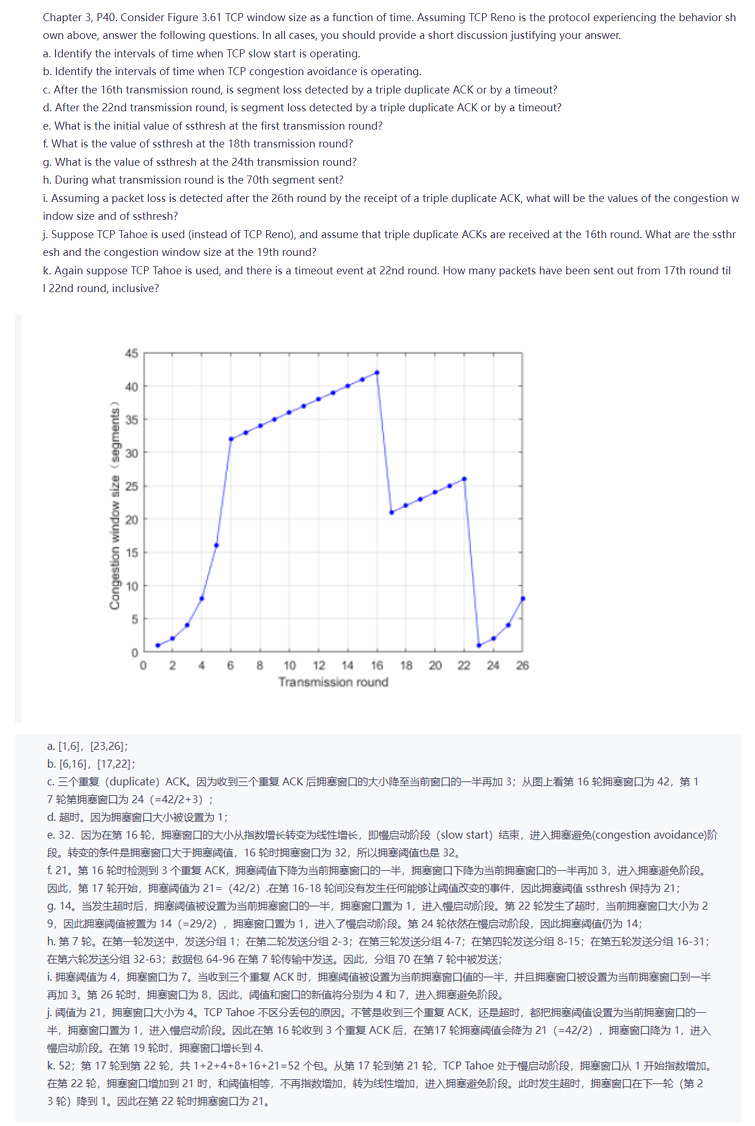
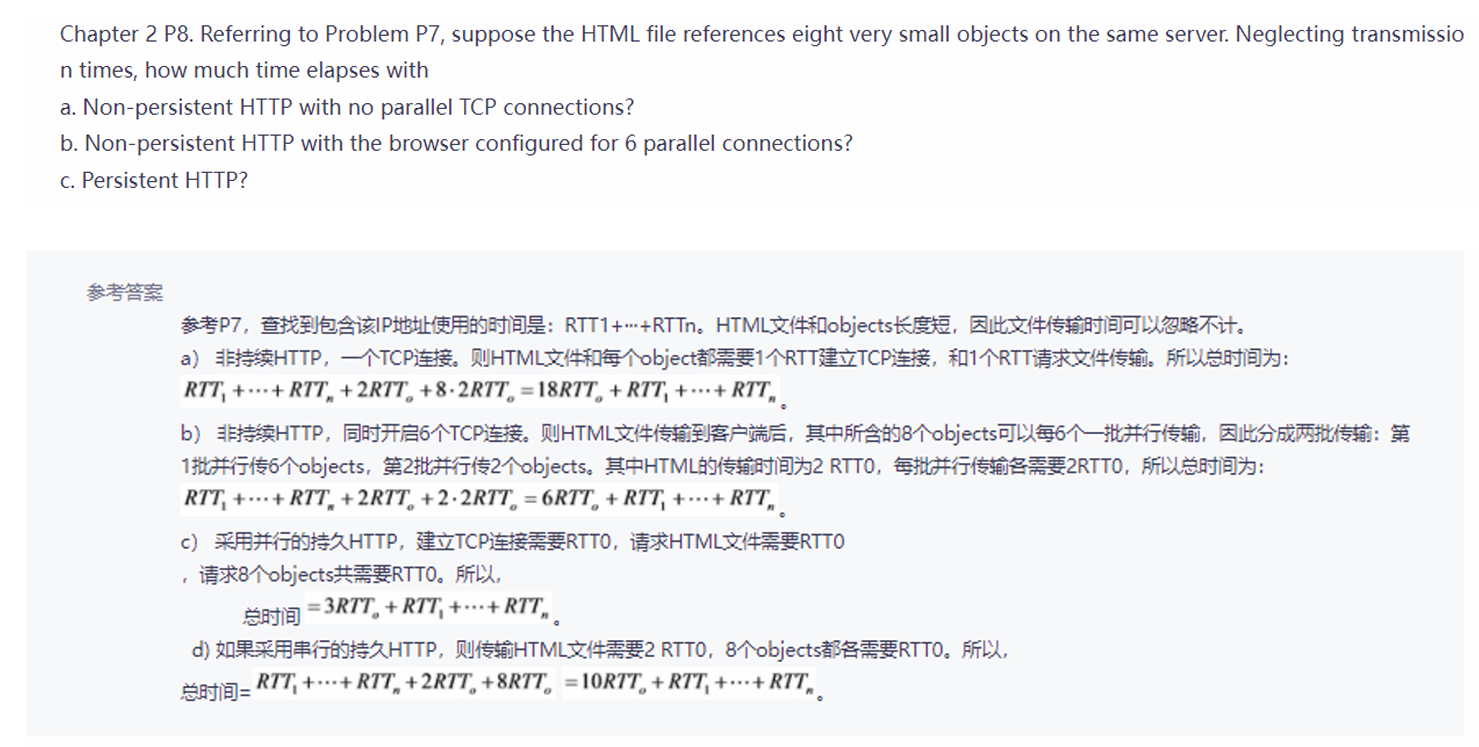
2022级
选择题
主机A和主机B之间建立了TCP连接,A向B发送了一个报文段,其中Seq=199,ack=200,数据部分有两个字节,则主机B对该报文的确认报文段中:
A. Seq = 201, ack = 200 B. Seq = 201, ack = 201 C. Seq = 200, ack = 201 D. Seq = 202, ack = 201
Seq(序列号)——表示发送的报文段中数据部分的第一个字节再A的发送缓存区中的编号
Ack(确认号)——表示A期望收到的下一个报文段的数据部分的第一个字节在B的发送缓存区中的编号。
发送两个字节,B发送Seq = A之前的ack 200; B即接收到数据后B准备发送的下一个字节序列号,Ack = 199+2字节=201
下列关于TCP和UTP的说法,错误的是:
A. TCP是面向连接的服务,在数据传输前要进行 三次握手
B. UDP提供一种不可靠数据传送服务,是无连接的。
C. UDP报文段中的确认号,用于接收方跟发送放确认报文接收
D. TCP拥塞控制主要包括慢启动、拥塞避免、快速回复等技术
基础知识。
下列关于TCP和UDP的说法,错误的是:
A. TCP是面向连接的服务,在数据传输前要进行三次握手
这是正确的。TCP(传输控制协议)是面向连接的协议,在数据传输前,双方需要通过三次握手(3-way handshake)来建立连接。B. UDP提供一种不可靠数据传送服务,是无连接的
这是正确的。UDP(用户数据报协议)是无连接的协议,不进行连接的建立,且不保证数据的可靠性。C. UDP报文段中的确认号,用于接收方跟发送方确认报文接收
这是错误的。UDP不使用确认号。UDP是无连接的,不会像TCP那样进行数据的确认和重传,因此其报文段中没有确认号字段。确认号是TCP协议中的概念,用于接收方告诉发送方其已收到的数据的字节序列号。D. TCP拥塞控制主要包括慢启动、拥塞避免、快速恢复等技术
这是正确的。TCP协议在数据传输过程中会进行拥塞控制,主要包括慢启动、拥塞避免、快速重传、快速恢复等算法来控制网络的拥塞情况,避免网络的过载。
考虑通过固定的路由从源主机发送数据包到目标主机,下面那个延迟可能会发生变化
A. 节点处理延迟 B.传输延迟 C.传播延迟 D.排队延迟
节点处理延迟 (Node Processing Delay)
节点处理延迟是指数据包在经过每个路由器或主机时的处理时间,包括检查数据包头部、转发数据包等。由于节点处理延迟依赖于设备的处理能力,一般情况下,如果路由器和主机配置固定,且处理能力不变,节点处理延迟是固定的。传输延迟 (Transmission Delay)
传输延迟是指数据包在传输媒介上传输所需的时间。它由数据包的大小和链路的传输速率决定。由于题目假设是固定路由,因此链路的带宽和数据包的大小也都是固定的,因此传输延迟也是固定的。传播延迟 (Propagation Delay)
传播延迟是指信号在传输介质中传播的时间,通常取决于信号传播的距离和介质的传播速度。如果路由是固定的,且链路的物理属性没有变化,那么传播延迟也是固定的。排队延迟 (Queuing Delay)
排队延迟是指数据包在路由器或交换机队列中等待转发的时间。排队延迟受网络流量、路由器负载以及队列管理策略等因素的影响。由于网络负载和流量变化,数据包在排队等待时所经历的延迟可能会发生变化。因此,排队延迟是最可能变化的延迟。
给定子网200.168.240/24,则该子网能支持的同时上网的用户数量和子网掩码是多少?
B. 254; 255.255.255.0
24—>255.255.255.0; 子网内剩余8个位置,2^8-2(排除网络地址和广播地址)实际254个
Persistent HTTP 与 Non-persistent HTTP区别在于
A. Persistent HTTP 不需要建立传输层的TCP连接
B. Persistent HTTP 在应用层与传输层之间采用Socket通信
C. Persistent HTTP 可以通过一个TCP链接获取多个对象(Objects)
D. Persistent HTTP 在两个RTT时间内只能传输一个对象(Object)
Persistent HTTP 允许在一个连接中传输多个对象,而不是限制在两个往返时间(RTT)内只能传输一个对象。事实上,Persistent HTTP 旨在减少连接建立的延迟(包括RTT),通过复用连接来提高效率。
关于P2P和C/S 网络应用架构,下列说法正确的是
A. P2P应用系统中的节点只能是客户端或者是服务器
B. P2P应用架构需要在TCP/IP协议增加功能来进行支持
C. 在P2P架构下,每个Peer既可以提供服务又可以请求服务
D. P2P架构总比C/S架构性能优越
A. P2P应用系统中的节点只能是客户端或者是服务器
这个说法是错误的。在 P2P(Peer-to-Peer)架构中,节点既可以充当客户端,也可以充当服务器,或者两者兼具。P2P架构的核心特点是每个节点(Peer)都可以同时提供服务和请求服务。因此,并不限制节点只能是客户端或服务器。B. P2P应用架构需要在TCP/IP协议增加功能来进行支持
这个说法也是错误的。P2P架构并不需要对TCP/IP协议做任何额外的修改或扩展。P2P应用可以在现有的TCP/IP协议栈之上实现,所有的通信都可以使用标准的TCP/IP协议进行,P2P的主要特点是节点之间的直接通信和资源共享。C. 在P2P架构下,每个Peer既可以提供服务又可以请求服务
这是正确的。P2P架构的一个重要特点就是每个节点既可以作为服务提供者,又可以作为服务请求者。每个Peer(节点)既可以向其他节点提供资源或服务,又可以从其他节点请求服务或资源。因此,P2P架构的灵活性非常高。D. P2P架构总比C/S架构性能优越
这个说法是错误的。P2P架构的性能不一定总是优于C/S(Client/Server)架构。C/S架构通常有明确的服务器角色,服务器负责处理大部分的请求和负载,适合高性能、高可靠性需求的应用。而P2P架构虽然可以通过分散的节点来分担负载,但在某些情况下(例如需要高效管理大量用户或资源时),P2P架构可能并不如C/S架构高效。因此,P2P架构的性能优劣取决于具体的应用场景。
下列关于CSMA/CA协议的说法错误的是
(Carrier Sense Multiple Access with Collision Avoidance,载波监听多路访问/冲突避免协议)
A. 在数据帧发送过程中能够检测到信道冲突(collision)
在 CSMA/CA 协议中,冲突是在发送数据之前通过“避免”而不是“检测”来处理的。具体来说,CSMA/CA 主要采用冲突避免机制,而不是像 CSMA/CD(Carrier Sense Multiple Access with Collision Detection,载波监听多路访问/冲突检测协议)那样在数据传输过程中检测冲突。在 CSMA/CA 中,节点通过监听信道并等待随机时间来避免冲突,而不是在数据帧发送过程中检测冲突。
B. 在发送数据帧前先监听信道状态
C. 检测到信道忙时,随即等待一段时间再继续监测信道
D.使用Stop-and-Wait可靠传输来应对信道冲突产生的丢包
下列说法中错误的是:
A. IP层可以频闭各个物理网络的差异
IP层通过统一的协议(如IPv4或IPv6)为上层提供一致的通信接口,使得不同物理层之间的差异对应用层透明。
B. IP层可以代替各个物理网络和数据链路层工作
IP层并不能代替物理网络和数据链路层的工作。IP层位于 OSI 模型的第三层,而物理层和数据链路层分别位于第一层和第二层。IP层负责路由和转发数据包,而物理和数据链路层负责在物理介质上传输数据帧,进行错误检测和流量控制等。
C. IP层可以隐藏各个物理为网络的实现细节
D. IP层可以提供转发和路由的功能
简答题
以下图网络拓扑为例,主机A向主机B发送数据。从网络层和链路层来简要描述数据发送的过程,并且说明在此过程中数据包头部的源和目的的MAC地址(12分)
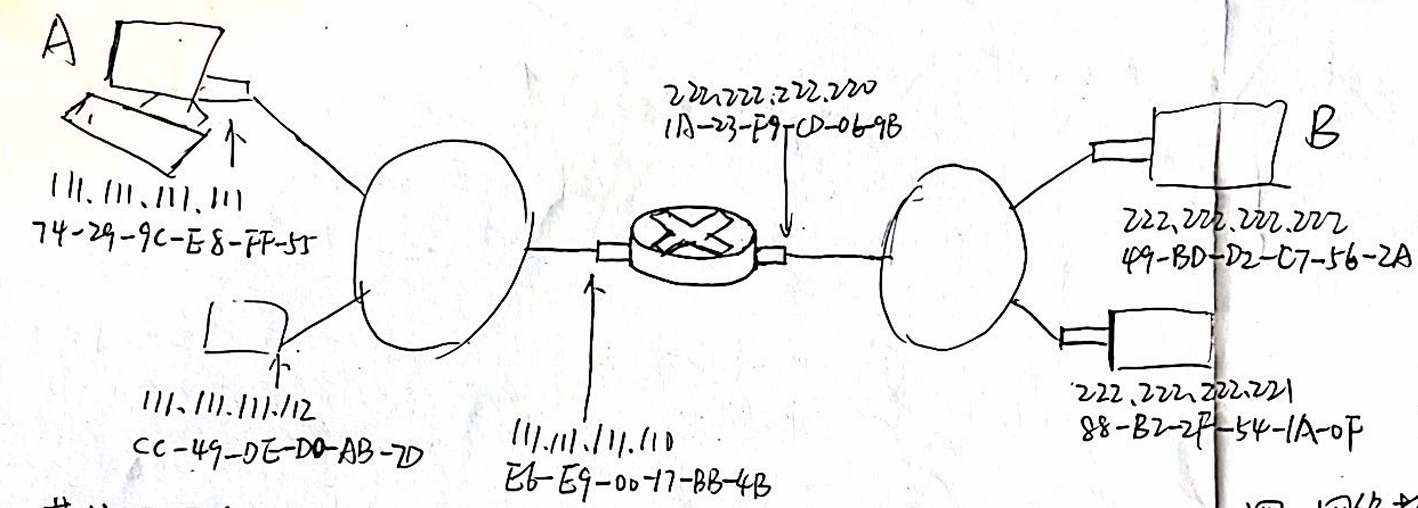
网络层:(IP地址)
- 主机A(源IP:111.111.111.111)将数据发送到主机B(222.222.222.222)
- 路由器是IP数据包转发的关键设备,通过IP地址来决定数据包转发路径
链路层(MAC地址)
- 主机A到路由器:
- 主机A (MAC:
74-29-9C-E8-FF-55) 将数据发送到路由器的接口 (MAC:E6-E9-00-77-BB-4B)。 - 数据帧头部的MAC地址:
- 源MAC地址:
74-29-9C-E8-FF-55 - 目的MAC地址:
E6-E9-00-77-BB-4B
- 源MAC地址:
- 主机A (MAC:
- 路由器处理数据包:MAC会变IP不变
- 路由器接收到数据帧后,解封装数据包,分析IP地址发现目标地址 (
222.222.222.222) 在其下一跳网络。 - 路由器将数据包重新封装成新的数据帧,准备发送给下一跳的主机B或其局域网中的设备。
- 路由器接口 (MAC:
E6-E9-00-77-BB-4B) 通过链路将数据发送给主机B所在网络的设备。
- 路由器接收到数据帧后,解封装数据包,分析IP地址发现目标地址 (
- 路由器到主机B:
- 路由器 (MAC:
1A-23-F9-CD-06-9B) 将数据发送到主机B (MAC:49-BD-D2-C7-56-2A)。 - 数据帧头部的MAC地址:
- 源MAC地址:
1A-23-F9-CD-06-9B - 目的MAC地址:
49-BD-D2-C7-56-2A
- 源MAC地址:
- 路由器 (MAC:
总结
数据发送过程中,源和目的MAC地址在不同链路上传输时会发生变化,但IP地址始终保持不变:
| 阶段 | 源MAC地址 | 目的MAC地址 | 源IP地址 | 目的IP地址 |
|---|---|---|---|---|
| 主机A -> 路由器 | 74-29-9C-E8-FF-55 | E6-E9-00-77-BB-4B | 111.111.111.111 | 222.222.222.222 |
| 路由器 -> 主机B | 1A-23-F9-CD-06-9B | 49-BD-D2-C7-56-2A | 111.111.111.111 | 222.222.222.222 |
以上即为数据从主机A到主机B的简要描述,包括网络层和链路层的工作以及MAC地址变化的过程。
某校园网有两个局域网通过路由器R1,R2和R3互联后接入Internet,S1和S2为以太网交换机。局域网采用静态IP地址配置,路由器部分接口一节个主机的IP地址如下图所示:
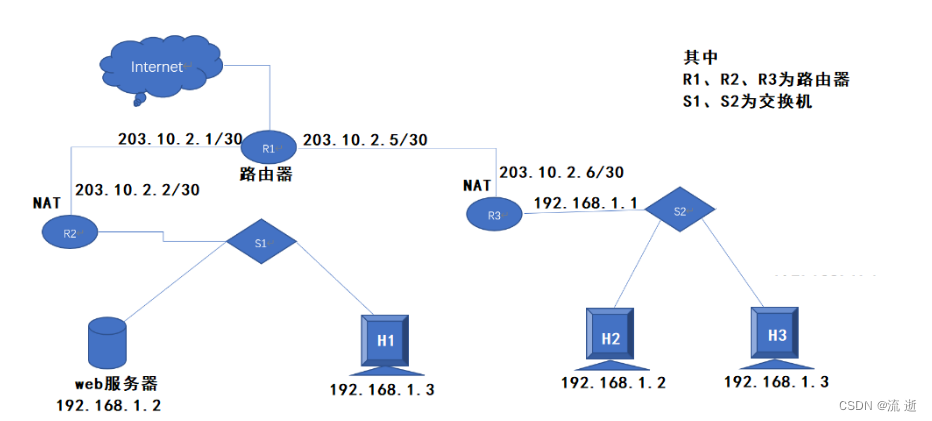

为使H2和H3能够访问Web服务器(使用默认端口号),需要进行什么配置?
H2、H3和Web服务器处于不同的局域网,路由器R2R3具有NAT功能。R2从WAN口收到来自H2H3的HTTP请求,根据NAT表发送给Web服务器的对应端口。为使外部主机能正常访问Web服务器,应在R2的NAT表中增加一项。外网的IP地址配置为路由器的外端IP地址,内网的IP地址配置为Web服务器的地址,HTTP服务器端的默认端口号的80
只需要在R2配置,因为我们只知道Web服务器端口号80,而客户端端口号随机分配,无法做静态配置,只能通过自动动态配置实现。
所以表:
| 外网 | 内网 | ||
|---|---|---|---|
| IP地址 | 端口号 | IP地址 | 端口号 |
| 203.10.2.2/30 | 80 | 192.168.1.2 | 80 |
若H2主动访问Web服务器,将HTTP请求报文封装到IP数据包P中发送,写出过程中的源IP和目标IP变化。三次改变
H2发送的P的源IP地址和目的IP地址分别是:192.168.1.2和203.10.2.2
R3转发后,P的源IP地址和目的IP地址分别是:203.10.2.6和203.10.2.2
R2转发后,P的源IP地址和目的IP地址分别是:203.10.2.6和192.168.1.2
网络拓扑如下图所示:
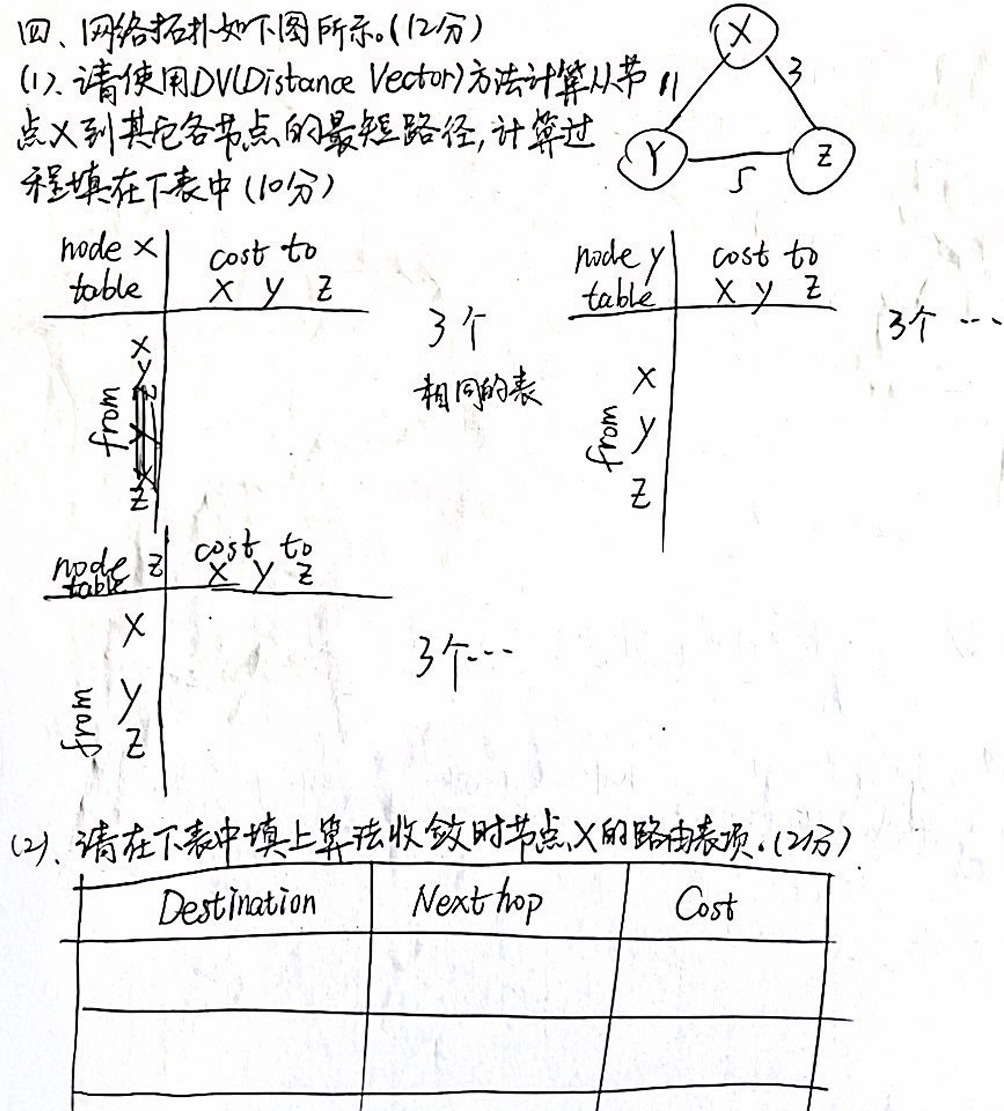
(1)CV计算从节点X到其他个节点的最短路径,计算过程写入下表:
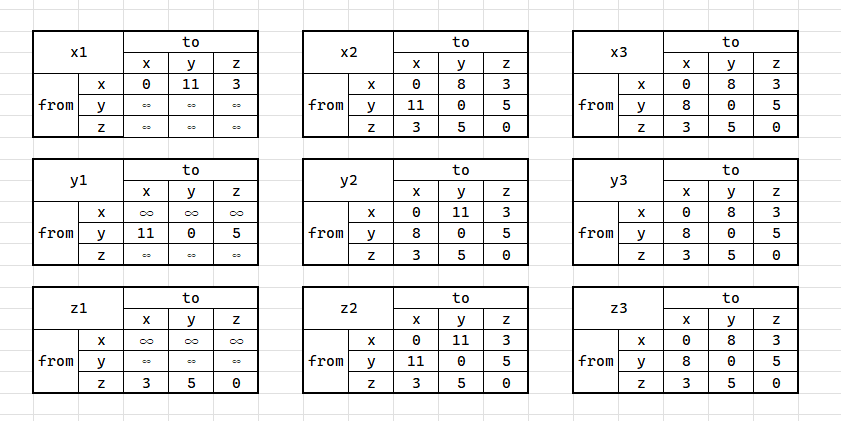
(2)在下表填入算法收敛时节点X的路由表项:
| Destination | Nexthop | Cost |
|---|---|---|
| x | 0 | 0 |
| y | z | 8 |
| z | z | 3 |
假设用户共享一条100Mbps的链路,又设每个用户传输数据时需要1Mbps的宽带,并且每个用户仅有10%的时间用于传输数据,其他时间空闲。
(1)如果使用电路交换(sircuit switching)最多能支持多少个用户?
在电路交换中,每个用户需要独占 1Mbps 的带宽进行数据传输。
链路总带宽为 100Mbps,因此最多能支持的用户数为:
$$
\text{最大用户数} = \frac{\text{链路总带宽}}{\text{每用户带宽}} = \frac{100 , \text{Mbps}}{1 , \text{Mbps}} = 100 , \text{个用户}
$$
(2)如果使用分组交换(packet switching)假定有N个用户,给出在任意时刻又多余M个用户时的传输概率表达式
在分组交换中,假设:
- NNN:总用户数。
- 每个用户有 p=10%=0.1p = 10% = 0.1p=10%=0.1 的概率在任意时刻发送数据。
- 任意时刻,多余 MMM 个用户同时发送数据的概率需要使用 二项分布。
概率表达式:
$$
P(X > M) = 1 - \sum_{k=0}^M \binom{N}{k} p^k (1-p)^{N-k}
$$
其中:
- X 是同时发送数据的用户数(服从二项分布)。
- \binom{N}{k} 是组合数,表示从 N 个用户中选择 k个用户同时发送数据的方式数。
- p^k 是 k 个用户发送数据的概率。
- (1-p)^{N-k} 是剩余 N−kN-kN−k 个用户不发送数据的概率。
(3)分析说明Internet采用分组交换的原因
电路交换的局限性
- 资源独占:在电路交换中,通信链路被独占,资源无法共享,导致利用率低。
- 浪费带宽:用户传输数据仅占用 10% 的时间,其余时间空闲,但链路资源依然被预留,造成浪费。
- 灵活性不足:电路交换需要为每个连接提前分配固定的带宽,无法动态适应网络流量变化。
分组交换的优势
- 高资源利用率:分组交换允许多用户共享链路,数据按需传输,不占用固定资源,极大提高了链路的利用率。
- 动态灵活:网络资源分配是按需进行的,能够适应用户传输数据的不确定性。
- 适应突发流量:分组交换能够处理网络流量的突发性,保证用户数据能够传输,即使偶尔发生拥塞也不会导致全局瘫痪。
- 支持多种服务:分组交换支持不同速率的数据流传输,适用于现代互联网需要传输多媒体数据(视频、语音、文本等)。
总结
Internet 采用分组交换,是因为它可以高效地共享网络资源,适应流量突发,降低资源浪费,满足现代互联网多用户和多业务传输的需求。
以下是图片中文字部分的转写内容:
六、实验在一条带宽宽裕的链路(图中 connection)上传输一个长度为 L 的数据分组。实验测得在时刻数据分组的第一个 bit 进入该链路,t 时刻数据分组的第一个 bit 离开该链路,t_2 时刻数据分组的最后一个 bit 离开该链路。各时刻示意如图所示,根据下述情况作答:(15 分)
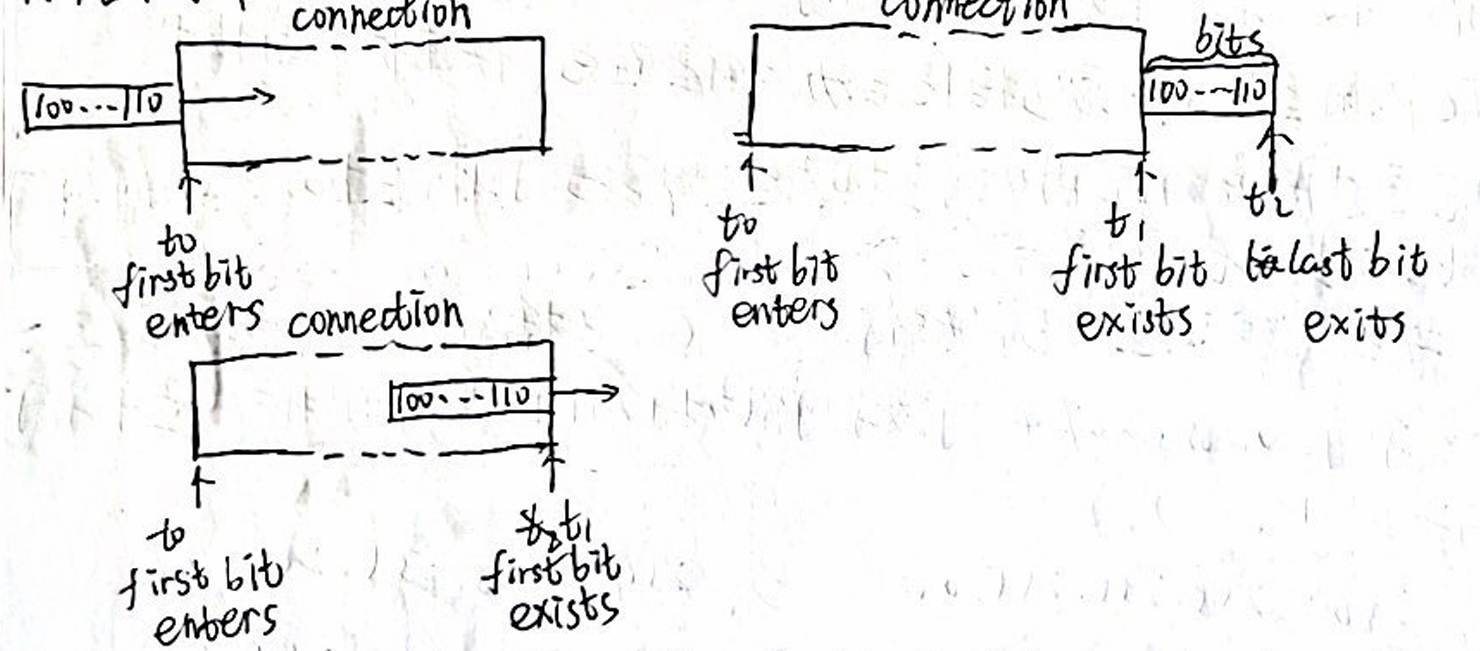
(1)使用上述实验中的变量符号表示该数据分组的传输延迟、传输延迟和吞吐率。(3 分)
传输延迟(Transmission Delay):指数据分组进入链路所需的时间,即数据分组的长度除以带宽:
$$
\text{传输延迟} = \frac{L}{B}
$$
- L:数据分组长度(bit)
- B:链路带宽(bit/s)
传播延迟(Propagation Delay):指信号在链路上传播的时间,与链路的长度 d 和信号传播速率 v 相关:
$$
\text{传播延迟} = \frac{d}{v}
$$
- d:链路长度(米)
- v:信号传播速率(米/秒)
吞吐率(Throughput):指单位时间内成功传输的数据量,等于带宽 B:
$$
\text{吞吐率} = B
$$
(2)写出端到端传输延迟计算公式(式中包含分组长度 sL)。(3 分)
端到端的传输延迟包括传输延迟、传播延迟和排队/处理延迟。不考虑排队和处理延迟时,公式为:
$$
\text{端到端延迟} = \text{传输延迟} + \text{传播延迟}
$$
将各部分代入:
$$
\text{端到端延迟} = \frac{L}{B} + \frac{d}{v}
$$
- L:数据分组长度(bit)
- B:链路带宽(bit/s)
- d:链路长度(米)
- v:信号传播速率(米/秒)
(3)假设链路往返时延为 100 ms,带宽为 1MB/s,计算发送一封分组长为 4KB 的 email 文件传输出链路所需的端到端传输延迟。(6 分)
- 分组长度
$$
L = 4 , \text{KB} = 4 \times 1024 \times 8 = 32768 , \text{bit}
$$
- 链路带宽
$$
B = 1 , \text{MB/s} = 8 \times 10^6 , \text{bit/s}
$$
- 往返时延 RTT=100 ms(单程时延为 RTT/2=50 ms)
步骤 1:计算传输延迟
$$
\text{传输延迟} = \frac{L}{B} = \frac{32768}{8 \times 10^6} = 0.0041 , \text{s} = 4.1 , \text{ms}
$$
步骤 2:传播延迟
单程传播延迟为50ms。
步骤 3:总延迟
$$
\text{端到端延迟} = \text{传输延迟} + \text{传播延迟}
$$
$$
\text{端到端延迟} = 4.1 , \text{ms} + 50 , \text{ms} = 54.1 , \text{ms}
$$
(4)按照和(3)同样的带宽和传播延迟假设,需要把 32GB 的数据从从天津交付给北京的朋友,时间紧急,时间和金钱,你会选择什么方式来完成?请说明原因。(3 分)
已知条件:
- 数据大小 32GB=32×1024×1024×8=2.68×10^11bit
- 链路带宽 B=1MB/s=8×10^6bit/s
计算传输时间:
$$
\text{传输时间} = \frac{L}{B} = \frac{2.68 \times 10^{11}}{8 \times 10^6} = 33500 , \text{s} \approx 9.3 , \text{小时}
$$
主机A通过TCP连接发送一个文件到主机B,TCP协议使用TCP Reno版本,下图画出了拥塞窗口岁时间变化的情况,其中发生的时间使用从1到6的序号进行标记,请回答:
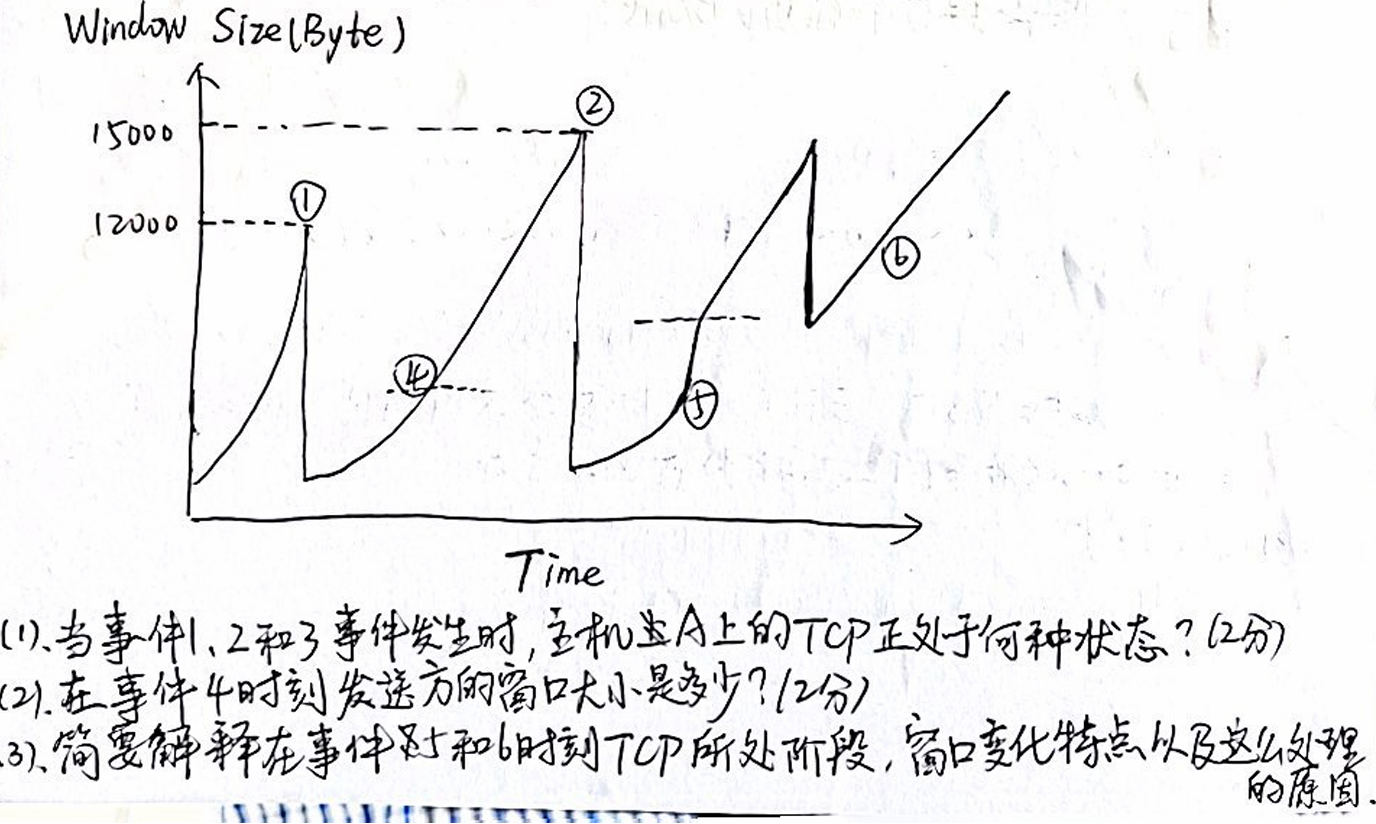
(1)
事件 1:窗口大小快速增长
- 此时 TCP 正处于慢启动阶段(Slow Start)。
- 在慢启动阶段,窗口大小(Window Size)按指数增长,即每收到一个 ACK,窗口大小翻倍。
事件 2:窗口大小达到最大限制(15000 字节)
- TCP 进入拥塞避免阶段(Congestion Avoidance)。
- 在拥塞避免阶段,窗口大小以线性增长的方式增加。
事件 3:窗口大小骤降
- 此时发生了数据丢失,TCP 检测到拥塞。
- TCP 进入拥塞控制阶段,通过快速重传或超时重传机制,窗口大小被重置。
(2) 7500Byte?
(3)慢开始和快恢复
事件 6:窗口大小重新开始增长
- TCP 重新进入拥塞控制阶段,但此时是拥塞避免阶段。
- 窗口大小呈线性增长,说明 TCP 逐渐恢复并试探网络的可用带宽。
简述CSMA/CD 中指数退避的基本思想并解释能够有效减少冲突的原因
CSMA/CD(Carrier Sense Multiple Access with Collision Detection)是一种用于有线局域网(如以太网)的介质访问控制机制,它通过“载波监听”和“冲突检测”来协调多个节点共享同一通信信道。
当发生冲突时,指数退避(Exponential Backoff) 算法被用于减少进一步冲突的概率。
基本思想
冲突检测:
- 当两个或多个节点同时发送数据,冲突会被检测到,发送数据的节点立即停止发送。
- 节点等待一段时间后重新尝试发送数据。
退避时间计算:
节点等待时间是随机选择的。
退避时间
按以下规则进行:
$$
\text{退避时间} = k \times \text{时间单位} , \text{(Slot Time)}
$$
其中:- kk:从区间[0, 2^n - 1] 中随机选择一个整数(n 是重传尝试次数,最多为 10 次)。
- 时间单位为网络的最小传输时延(Slot Time)。
指数退避:
每当发生一次冲突,等待的时间范围(区间)会
指数增加
:
- 第一次冲突:k∈[0,1]k \in [0, 1]
- 第二次冲突:k∈[0,3]k \in [0, 3]
- 第三次冲突:k∈[0,7]k \in [0, 7]
- …
- 第 nn 次冲突:k∈[0,2n−1]k \in [0, 2^n - 1]
这样,随着冲突次数的增加,节点等待的时间间隔变得更长,减少了短时间内再次发生冲突的概率。
有效减少冲突的原因
- 随机退避机制:
每个节点在重新发送前都会随机选择等待时间,这样可以避免两个节点在相同时间再次发送数据,从而减少连续冲突的概率。 - 退避时间指数增加:
随着冲突次数的增加,退避时间范围会指数增长。这意味着当网络负载较高、冲突频繁时,节点会等待更长的时间再重试,给其他节点更多的机会发送数据,从而逐渐缓解网络拥塞。 - 动态调整机制:
指数退避是自适应的,它根据冲突的严重程度动态调整退避时间。在轻载情况下,节点可以快速重传;在重载情况下,退避时间较长,冲突概率自然降低。
2023级
这里感谢我的舍友在考完后立马给我的一手资料(跪

NAT转换表、交换机自学习、MAC IP地址变化
分组交换、电路交换 端到端延迟
网络拓扑Dijkstra 路由表
停等类和流水线类 更大链路利用率
DNS主要功能 基本工作原理 分布式设计原因
TCP Reno
CSMA/CD是那种网络采用的MAC协议、基本原理;多用户竞争情况下,能高效利用链路,分析其中所采取的机制或措施

