软件安全实验1-6详解
太喜欢这门课,而且是越写实验越好玩!找到了《软件安全:漏洞利用及渗透测试》这本书,其中有更多的实验,打算在之后的寒假慢慢补上。
或许也是想给学弟学妹留下点什么,就结合了一些班里同学问过我的一些问题或者可能会出问题的点,打算详细的把这个实验 是什么、为什么、怎么做告诉大家。
同时也希望大家在实验过程中有一些自己的思考和感悟,欢迎批评指正。
实验一:PE文件代码注入实验(winmine)
通过本实验,预期达到以下实验目的:
熟悉PE文件格式。
复习汇编语言常见指令。
学习查看,编辑,保存PE文件。
熟练使用LoadPE和OllyDbg调试工具。
一. 实验步骤
1. 首先了解PE文件格式:
查资料:PE 全称是 Portable Executable,即可移植的可执行文件,是 Windows 操作系统下可执行文件的总称,是用于存储可执行文件 (exe, scr)、动态链接库 (dll, oxc, cpl) 和驱动程序 (sys, vxd) 的标准文件格式。
PE 文件结构复杂而丰富,它包含了可执行文件的所有必要信息,以便操作系统正确加载和执行程序。
通过这个扫雷程序了解PE文件结构:
- DOS头(DOS Header+ DOSStub)
PE 文件的开头通常包含一个 DOS 头,用于向后兼容早期的 MS-DOS 操作系统,使得 DOS 识别出这是有效的执行体,然后运行紧随之后的是 DOS Stub
DOS Header 由一个 0x40 大小的 IMAGE_DOS_HEADER 结构体组成:
1 | typedef struct _IMAGE_DOS_HEADER { // DOS .EXE 文件头结构体 |
其中主要关注 e_magic 和 e_lfanew 这两个成员变量。e_magic 位于文件首,其值对应的 ASCII 为 MZ,标识该文件为可执行文件;e_lfanew 的值表示 PE 头的偏移地址

DOS Stub 在多数情况下由汇编器/编译器自动生成,由代码和数据混合而成,大小不固定,在不支持 PE 文件格式的操作系统中,它将简单显示一个错误提示。不需要过多关注,在 Windows OS 下不会运行这部分代码,但在DOS环境中可以运行。
- NT头
NT 头是 PE 文件的核心部分,也是 PE 头的一部分,包含了有关可执行文件的重要信息。PE 头的开始位置由 DOS 头中的 e_lfanew 字段指定。在 32 位下这个结构体由一个 0xf8 大小的 IMAGE_NT_HEADERS 结构体组成,该结构中包含了 PE 文件被载入内存时需要用到的重要域,该结构体的大小为0xf8字节,如下:
1 | typedef struct _IMAGE_NT_HEADERS { |

50 45 00 00 PE签名
4C 01 CPUMachine码
03 00 节区数目
0B 01 之后是可选头
0B 01可选头类型
21 3E 程序入口
指向程序入口RVA
0x10C 镜像基址
0x110 0x114对齐大小
0x120主子系统版本号
0x128镜像中内存大小
- 节表区:
*节表描述了 PE 文件中各个节的布局和属性,其位于 NT 头之后,也是 PE 头的最后一个部分:
*节区表记录了 PE 文件中所有节区的相关属性,节区表由一系列的 IMAGE_SECTION_HEADER 结构排列而成,每个结构用来描述一个节,结构的排列顺序和它们描述的节在文件中的排列顺序是一致的。全部有效结构的最后以一个空的 IMAGE_SECTION_HEADER 结构作为结束,所以节表中 IMAGE_SECTION_HEADER 结构数量等于节的数量加一。IMAGE_SECTION_HEADER 结构体大小为 0x28 字节
- PE 文件其余特定区域:
再继续往下便是真真正正的 text 节,data 节,rsrc 节。
一个典型的PE文件中包含的节如下:
(1).text:由编译器产生,存放着二进制的机器代码,也是我们反汇编和调试的对象。
(2).data: 初始化的数据块,如宏定义、全局变量、静态变量等。
(3).idata:可执行文件所使用的动态链接库等外来函数与文件的信息, 即输入表。
(4).rsrc: 存放程序的资源,如图标、菜单等。
除此以外,还可能出现的节包括“.reloc”、“.edata”、“.tls”、“.rdata”等。
# 数据目录表、导入表、导出表、资源表、重定位表、甚至还有其他自定义部分,如 TLS 表(线程局部存储表)、加载配置表 (Load Configuration Table) 等,这些部分包含了各种附加信息和配置…
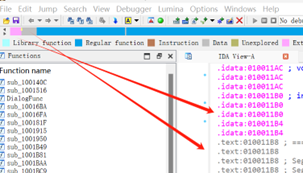

- 导入表&导出表
在 Windows 程序逆向中,我们能从这两个表中获取到许多非常重要信息
导入表(IAT表):
由于入口地址的不确定性,程序在不同的电脑上很有可能会出错,为了解决程序的兼容问题,操作系统就必须提供一些措施来确保程序可以在其他版本的Windows操作系统,以及DLL版本下也能正常运行。这时IAT表就应运而生了。
每个 exe 或者 dll 一般都会有它的导入表,记录了其自身会使用到的其他模块导出的函数。即记录调用了哪些模块 (dll),以及调用了它里面的哪些函数
导入表的意义是确定 PE 文件依赖哪个模块的哪个函数,以及确定模块加载进内存后具体函数的地址一个导入表的大小是 0x14 字节,
导入表跟导出表不同,导出表只有一个,里面有子表进行记录。而导入表是依赖每的一个模块都会有一个对应的导入表
导出表:记录导出符号的地址、名称、序号。一般来说需要提供功能的二进制程序(一般为 dll 文件)才会有导出表,可以通过导出表分析如下信息:
- 此动态链接库文件提供了什么功能
- 向调用者提供输出函数(供使用者调用的函数)在模块中的起始地址
导入表中需要重点关注的三个成员:
- DUMMYUNIONNAME & FirstThunk
这两个成员用于确定依赖的函数的名称。DUMMYUNIONNAME 指向 INT (导入名称表, Improt Name Table);FirstThunk 指向 IAT(导入地址表, Improt Address Table, 类似 elf 的 GOT 表)

用于确定依赖的模块的名字。记录一个 RVA 地址,指向依赖的模块的名字(如”xx.dll”)这个字符串
在逆向分析中,我们可以通过 dll 名和 dll 导出函数的名字得到这个函数的地址,当然也可以通过代码获取,有很多 API 可供我们进行调用,如下
- 通过 Loadlibrary(GetModelHandle) 将 dll 模块映射进内存并返回一个可以被 GetProcAddress 函数使用的句柄
- 利用 GetProcAddress 函数获得 dll 的加载地址,然后遍历导出表就可以得到函数地址
- 这里还需要提及的一个概念:虚拟内存:
* 在Windows系统中,在运行PE文件时,操作系统会自动加载该文件到内存,并为其映射出4GB的虚拟存储空间,然后继续运行,这就形成了所谓的进程空间。用户的PE文件被操作系统加载进内存后,PE对应的进程支配了自己独立的4GB虚拟空间。在这个空间中定位的地址称为虚拟内存地址(Virtual Address,VA)。
静态分析工具看到的PE文件中某条指令位置是相对于磁盘文件而言的,即所外的文件偏移。而动态调试时,我们才能知道这条指令在内存中所处的位置,即虚拟内存地址
PE文件地址和虚拟内存地址之间映射关系的几个重要概念:
文件偏移地址(File Offset)
数据在PE文件中的地址叫文件偏移地址,是文件在磁盘上存放时相对文件开头的偏移。
装载基址(Image Base)
PE装入内存时的基地址。默认情况下,EXE文件在内存中的基地址是0x00400000,DLL文件是0x10000000。这些位置可以通过修改编译选项更改。
虚拟内存地址(Virtual Address, VA)
PE文件中的指令被装入内存后的地址。
- 相对虚拟地址(Relative Virtual Address, RVA)
相对虚拟地址是内存地址相对于映射基址的偏移量。
一个很重要的概念!!下一个实验也用到了:
在默认情况下,一般PE文件的0字节将对映射到虚拟内存的0x00400000位置,这个地址就是所谓的装载基址(Image Base)。
文件偏移是相对于文件开始处0字节的偏移,RVA(相对虚拟地址)则是相对于装载基址0x00400000处的偏移。由于操作系统在进行装载时“基本”上保持PE中的各种数据结构,所以文件偏移地址和RVA有很大的一致性。
之所以说“基本”上一致是因为还有一些细微的差异。这些差异是由于文件数据的存放单位与内存数据存放单位不同而造成的。
(1)PE文件中的数据按照磁盘数据标准存放,以0x200字节为基本单位进行组织。当一个数据节(section)不足0x200字节时,不足的地方将被0x00填充:当一个数据节超过0x200字节时,下一个0x200块将分配给这个节使用。因此PE数据节的大小永远是0x200的整数倍。
(2)当代码装入内存后,将按照内存数据标准存放,并以0x1000字节为基本单位进行组织。类似的,不足将被补全,若超出将分配下一个0x1000为其所用。因此,内存中的节总是0x1000的整数倍。
2. 汇编常见指令
在汇编语言中,主要有以下几类类寄存器:
·4个数据寄存器(EAX、EBX、ECX和EDX)
·2个变址寄存器(ESI和EDI) 2个指针寄存器(ESP和EBP)
·6个段寄存器(ES、CS、SS、DS、FS和GS)
·1个指令指针寄存器(EIP) 1个标志寄存器(EFlags)
3. 实验操作:
检查程序加壳情况:
用OllyDBG打开扫雷程序:
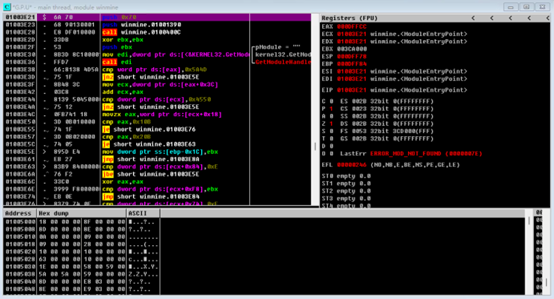
程序停在了0x01003E21的位置,这个就是程序的入口点。同样也可以通过LordPE,得知程序RVA为0x01003E21,同样可以看到装载基址是0x01000000(这里可以看出扫雷程序是C++编写);右侧寄存器EIP值0x01003E21后标识ModuleEntryPoint!
往下翻可以看到相关的导入表动态连接库及其相关函数信息:

往下翻可以看到大量空白代码区域,这段区域.data是代码区,如果我们在这里植入代码,再修改PE文件跳转入口,可以实现相关的植入代码执行
我们看MessageBox:
以下我们编辑注入代码:
因为我们选择的A类函数,我们直接编辑db类型的ascii码即可,输入后按A分析。
我们可以注意到,每行语句后都留有00,因为字符串后面是需要结束符0x00的。
题目要求弹框后进入正常运行,所以我们需要先调用弹窗函数,再跳转到一开始的程序入口位置。
在输入汇编指令call MessageBoxA、jmp start后能直接识别,是因为PE文件中已经有这个函数的相关分析,直接引用。
下面是修改后的状态:

用PEeditor修改程序入口为0x1004ABF,注入成功!


点击保存,运行程序,弹出弹窗,运行程序。

如果用IDA修改:

查壳
首先在数据段找一段空白处插入字符串:

找一段有可执行权限的内存注入指令,调用 call MessageBoxA 需要通过动态调试查看相应函数在动态链接库的地址
很糟糕,动调也没看到这个函数:(运行环境win11)
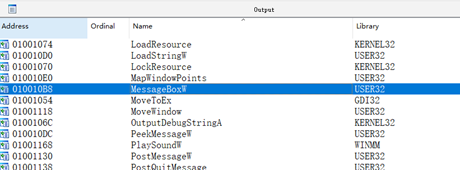
这里我们改用MessageBoxW,unicode输入:
*+长度可以定义dw长度:
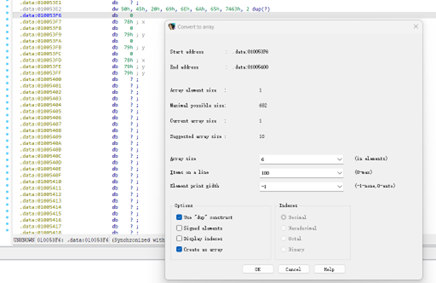
像刚刚ollygbd里一样修改:
记录程序入口01005403(修改刚刚的rva
这里我们用010editor直接修改程序入口点

实验二:基于UAF漏洞泄漏glibc基地址实验
程序编译开启了随即地址保护,为了使前后一致,都使用的同一次实验截图
这里是运行源代码:
1 |
|
运行即可得到:
1 | p = 0x1b5b010 |
如何正确运行:
实验要求:64位Ubuntu 16.04操作系统,glibc-2.23.
因为不同的可执行文件对于libc版本有不同的要求,为了不用遇到一个类型的libc装一个类型的libc,这里用glibc-all-in-one工具进行版本管理
(如果只做这一次实验,推荐是直接装glibc2.23)
1 | ┌──(kali㉿kali)-[~/glibc-all-in-one] |
接着用patchelf修改本地程序链接libc版本:
1 | ┌──(kali㉿kali)-[~/Desktop] |
如何快速证明main_arena和libc_base输出是正确的位置:
libc_base:
这里我是用IDA远程连接kali动态调试:
此时我们点击malloc函数 跳入函数调用表 再点击进入libc函数 最后点击就是malloc函数的位置

往上翻可以看到libc_base地址 0x7f5a92200000

main_arena:
main_arena中布局为 88位 ,第一个申请的unsorted的堆的位置-0x88就是main_arena位置
对每一块的解释
以下是对每一块我不理解的东西的一些解释,探索过程是从后往前的,但是解释是从前往后的,所以最后一块写了很多多余的东西,找到自己想知道的就行。
为什么要申请0x80大小的malloc:
一个快速的了解堆:堆漏洞挖掘中的bins分类(fastbin、unsorted bin、small bin、large bin)
一个极致详细的了解堆:[glibc heap——从入门到入土 ](http://jmpcliff.top/2124/04/21/Blog/Pwn/pwn note/glibc-heap/glibc heap从入门到入土/)
fastbins为单链表存储。unsortedbin、smallbins、largebins都是双向循环链表存储。
free掉的chunk,如果大小在0x20~0x80之间会直接放到fastbins上去,大于0x80的会放到unsortedbin上,然后进行整理。
我们要利用这个双向循环列表的unsorted特性,来对UAF进行实验,这就是为什么选择申请0x80的大小
为什么要找main_arena的位置
UAF——Use after free(Use After Free - CTF Wiki)
程序在创建堆的时候是会调用__malloc_hook的,这里如果我们将这个hook的指向地址替换为可控制的程序函数地址就可以执行我们需要的shellcode,所以我们需要定位__malloc_hook,而在libc-2.23中,hook的位置是main_arena的位置减0x10
怎么找到Main_arena位置呢/为什么-88?
首先我们需要知道什么是arena:
这篇博客写的很清楚:什么是Arena
管理堆的部分程序称为堆管理器,堆管理器处于用户程序与内核中间,其工作为malloc和free(分配和回收堆空间)
堆的glibc实现包括struct _heap_info,struct malloc_state,struct malloc_chunk这3个结构体。
Arena就是来管理线程中这些堆的信息
一个线程只有一个arena,并且这些线程的arnea都是独立的不是相同的。主线程的arnea称为main_arena,相对子线程为thread_arena
Arena实现的struct malloc_state:
1 | struct malloc_state |
解释1
要求mfastbinptr fastbinsY[NFASTBINS];

先求MAX_FAST_SIZE,进入SIZE_SZ
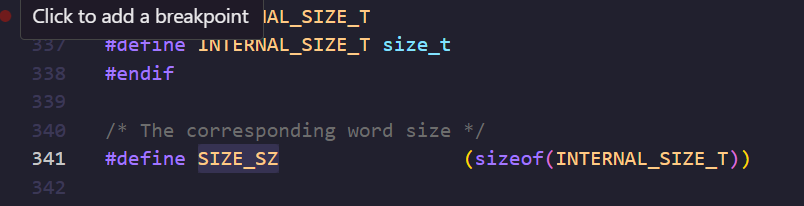
SIZE_SZ为8字节,所以这时候MAX_FAST_SIZE就是0xA0

request2size(0xA0)//将需求size转换为申请的chunk_size–> 0xB0
fastbin_index(0xB0)+1 —> 0xB-2+1=0xA

一个int8字节,0xA*8 = 0x50

解释2
1 | /* Base of the topmost chunk -- not otherwise kept in a bin */ |
[关于bins中的1mol东西](http://jmpcliff.top/2124/04/21/Blog/Pwn/pwn note/glibc-heap/glibc heap从入门到入土/#bins数组)
为什么减0x3c4b20?
知道了刚刚那些奇奇怪怪的东西,自然也就知道为什么了。
以下是刚拿到这个代码时提出的问题,在逆向探究时候,部分解释根据逻辑顺序放到了上面。
先定位libc-2.23中的0x3C4B20位置,看看有什么:
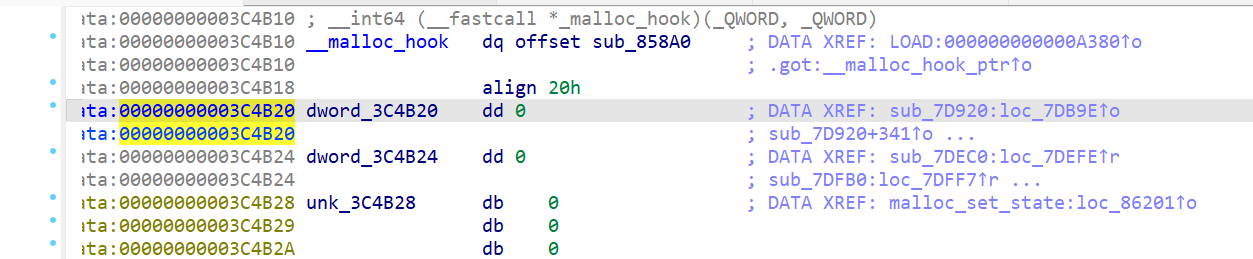
欸?上面怎么是malloc_hook呢?而且只差了0x10的偏移,搜搜malloc_hook 研究.
文中指出,__malloc_hook是glibc定义的一组变量,即函数指针,由此去调用对应的函数,所以称为hook,在运行的程序中(也只有运行中的程序才能看到,因为堆是动态分配)也能看到,

我们反编译libc-2.23.so文件,对照着看:
先来到*p的地址,因为我们开辟了0x80大小的位置,所以不会在fastbin中分配(fastbin大小为0x58,也就是80)
char *p = malloc(0x80);
malloc的行为——malloc 函数返回对应大小字节的内存块的指针,所以*p是这个堆的地址
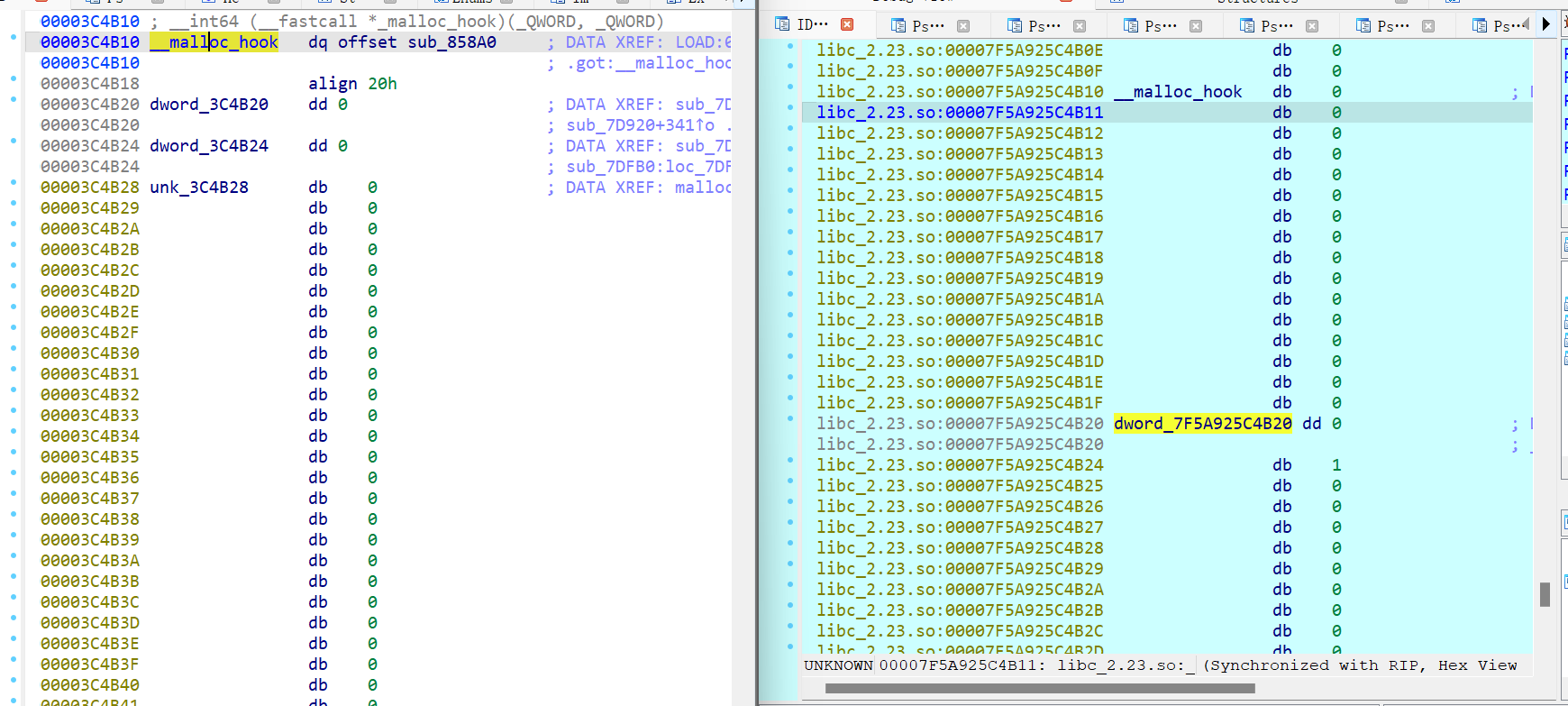
以上是我对UAF实验中这段代码和代码行为的全部问题与探索。
整点好玩儿的UAF-pwn题
[NISACTF 2022]UAF
看到backdoor!但这个后门函数没有被调用,所以我们在传入sh之后还需要调用这个函数

page[0]不可写,这就要利用UAF来绕过对page 0写的限制:
申请page 0后释放,再申请page 1,此时获得的指针还是指向之前分配给的page 0
修改page 0中的内容,show展示page 0,即可调用通过payload篡改的地址,即后门函数,getshell!

后话
结束!爽了!彻底搞清楚了!!!!!从吃饭回来到0点!
(鞠躬!
感谢Jmp.Cliff师傅对struct malloc_state的超详细解读和队友对于我各种奇怪的问题的解答)
实验三:Shellcode编写实验
一. 实验环境
Windows XP操作系统。
二. 实验目的
基于给定的示例程序:
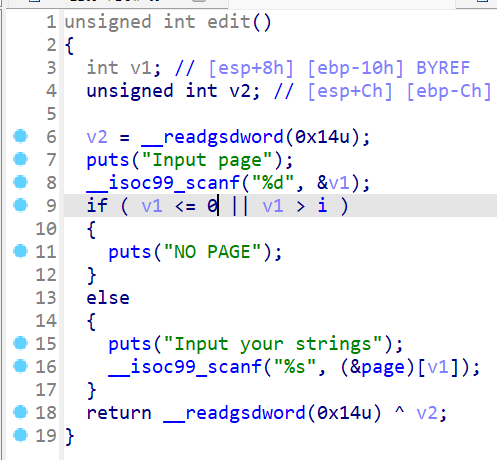
分析代码并理解存在的缓冲区溢出漏洞
编写shellcode利用发现的缓冲区溢出漏洞实现一个弹出对话框的功能
三. 实验步骤
弄清楚程序有几个输入点,这些输入将最终会当作哪个函数的第几个参数读入到内存的那一个区域,哪一个输入会造成栈溢出,在复制到栈区的时候对这些数据有没有额外的限制等。调试之后还要计算函数返回地址距离缓冲区的偏移并淹没之,选择指令的地址,最终制作出一个有攻击效果的“承载”着shellcode的输入字符串。
这里分析上课提到的函数:
1 |
|
分析程序代码是否存在漏洞,若存在则
如何利用漏洞实现执行任意代码(例如弹出一个对话框)?
Verify函数的缓冲区44个字节,拿过来上课的ppt中栈帧结构,改一下:
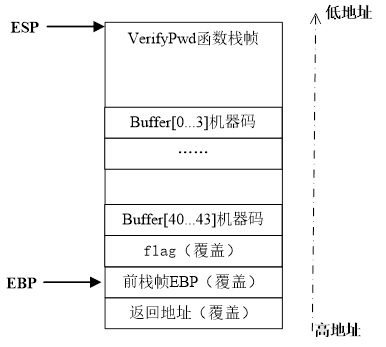
可以看到这里的漏洞在strcpy
为了能覆盖返回地址,需要在reg.txt中至少写入:buffer(44字节)+flag(4字节)+前EBP值(4字节),也就是53-56字节才是要淹没的地址。
MessageBox在第一次实验报告中简单的提及,这里说汇编语言调用MessageBoxA的步骤:
(1)装载动态链接库user32.dll。MessageBoxA是动态链接库user32.dll的导出函数。虽然大多数有图形化操作界面的程序都已经装载了这个库,但是我们用来实验的consol版并没有默认加载它。
(2)在汇编语言中调用这个函数需要获得这个函数的入口地址。
(3)在调用前需要向栈中按从右向左的顺序压入MessageBoxA的4个参数。
为了让植入的机器代码更加简洁明了,我们在实验准备中构造漏洞程序的时候已经人工加载了user32.dll这个库,所以第一步操作不用在汇编语言中考虑。
第一步:获得函数入口地址
有两种方式,第一是根据工具和偏移来计算函数入口(user32.dll 的基地址为0x77D10000,MessageBoxA的偏移地址为0x000407EA。基地址加上偏移地址就得到了MessageBoxA函数在内存中的入口地址:0x 77D507EA。);另一个方法,使用代码来获取相关函数地址,在C/C++语言中,GetProcAddress函数检索指定的动态链接库(DLL)中的输出库函数地址。如果函数调用成功,返回值是DLL中的输出函数地址。函数原型如下:
1 | FARPROC GetProcAddress( |
参数hModule包含此函数的DLL模块的句柄。LoadLibrary、AfxLoadLibrary或者GetModuleHandle函数可以返回此句柄。参数lpProcName是包含函数名的以NULL结尾的字符串,或者指定函数的序数值。如果此参数是一个序数值,它必须在一个字的低字节,高字节必须为0。FARPROC是一个4字节指针,指向一个函数的内存地址,GetProcAddress的返回类型就是FARPROC。如果你要存放这个地址,可以声明以一个FARPROC变量来存放。
1 |
|
运行上述代码后,同样可以得到MessageBoxA函数在内存中的入口地址:0x77D507EA。

对应汇编代码
参考ppt里的函数调用汇编代码:
1 | Shellcode( push 0的机器码会出现0x00,会造成字符串读取截断。) |
机器码:(右下角)


拿出来,换个格式,很好的替换方法:
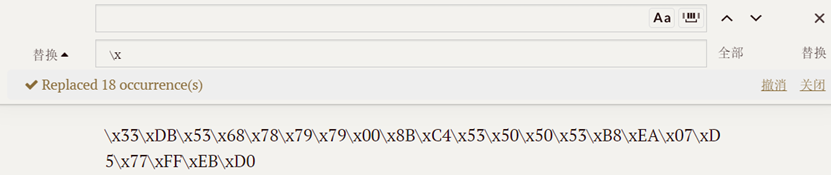
机器码
shellcode = \x33\xDB\x53\x53\x53\x53\xB8\xEA\x07\xD5\x77\xFF\xD0

验证机器代码
可以运行
1 | _asm |

接下来就可以利用这个Shellcode来实现漏洞的利用了。
自己编写调用Messagebox输出自定义字符的Shellcode:
根据以上操作,继续
\x33\xDB\x53\x68\x78\x79\x79\x00\x8B\xC4\x53\x50\x50\x53\xB8\xEA\x07\xD5\x77\xFF\xD0
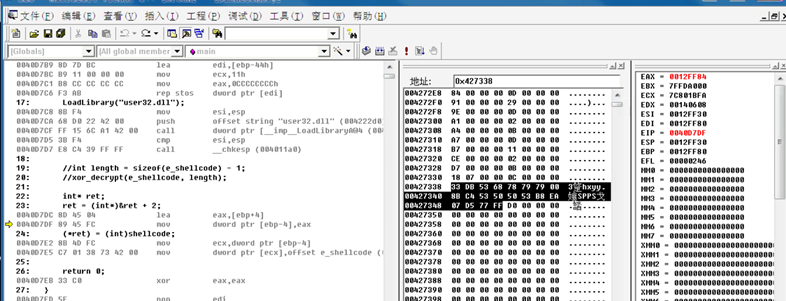

神奇。
**加密shellcode **
这里使用异或编码
有些需要注意:在选取编码字节时,不可与已有字节相同,否则会出现0。

- 很好的和0x07异或,orz哭了

加密后shellcode:
\x3B\xD3\x5B\x60\x70\x71\x71\x08\x83\xCC\x5B\x58\x58\x5B\xB0\xE2\x0F\xDD\x7F\xF7\xD8
动态调试看程序在返回时,需要跳转的位置:
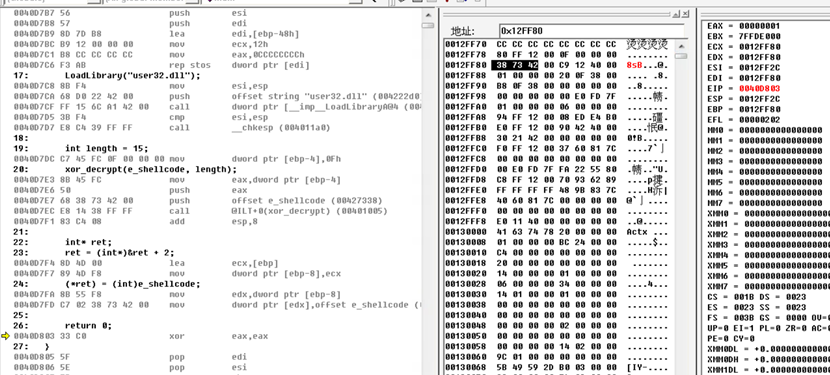
往后执行,跳转到高亮的后一个单位0x4012C9,所以需要 ret+1
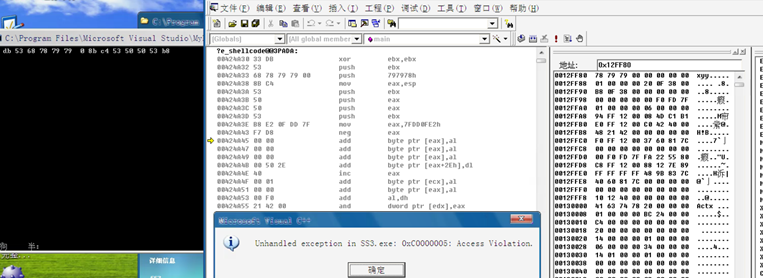
跳过来了
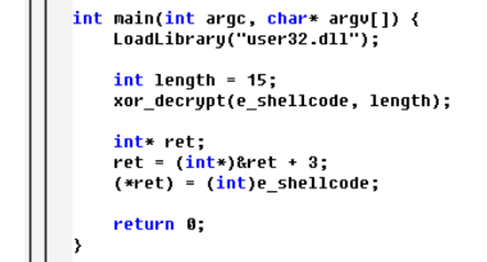

这里是增加了一个变量int length,导致ret距离main多4字节,也可如图中所示代码修改:

Ppt中有提到,直接将shellcode写为 “加密的指令和解密代码的汇编”,感觉会比我的操作更简单一点:
运行抓到如下程序的机器码:

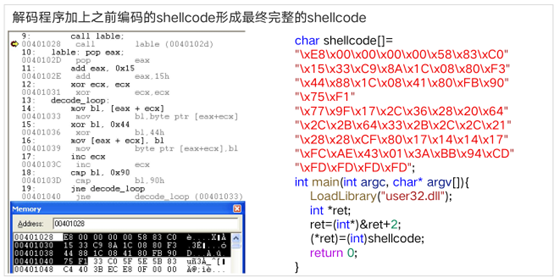
实验四:API自搜索技术
一. 实验环境
Windows10操作系统。
二. 实验目的
\1. 掌握ASLR安全防护机制;
\2. 掌握API自搜索技术;
\3. 学会在Windows10环境下弹出对话框需要的步骤。
三. 实验步骤
ASLR安全防护机制:
ASLR是地址空间分布随机化的简称,通过将系统关键地址随机化,使得之前硬编码shellcode失效。Shellcode需要调用一些系统函数才能实现系统功能达到攻击目的,而这些函数地址一般为 系统dll、可执行文件本身、栈数据或者PEB(进程环境块)中固定调用地址。
在Windows Vista上,当程序启动将执行文件加载到内存时,操作系统通过内核模块提供的ASLR功能,在原来映像基址的基础上加上一个随机数作为新的映像基址。随机数的取值范围限定为1至254,并保证每个数值随机出现。
ASLR通过增加随机偏移,使得很多攻击变得非常困难。但是,ASLR技术存在很多脆弱性,包括:
(1)为了减少虚拟地址空间的碎片,操作系统把随机加载库文件的地址限制为8位,即地址空间为256,而且随机化发生在地址前两个最有意义的字节上;
(2)很多应用程序和DLL模块并没有采用/DYNAMICBASE的编译选项;
(3)很多应用程序使用相同的系统DLL文件,这些系统DLL加载后地址就确定下来了,对于本地攻击,攻击者还是很容易就能获得所需要的地址,然后进行攻击。
针对这些缺陷,还有一些其他绕过方法,比如攻击未开启地址随机化的模块(作为跳板)(利用ESP寄存器特性,返回地址动态定位)、堆喷洒技术(slide code-noooop)、部分返回地址覆盖法等。
API自搜索技术
随着系统版本的变化,很多函数的地址也会随之变化,之前我们采用硬编址的方式来调用API函数,可能调用就失效了,这里我们编写shellcode必须具备动态的自动搜索所学的API函数地址能力,这个就是API自搜索技术。
·MessageBoxA位于user32.dll中,用于弹出消息框。
·ExitProcess位于kernel32.dll中,用于正常退出程序。所有的Win32程序都会自动加载ntdll.dll以及kernel32.dll这两个最基础的动态链接库。
·LoadLibraryA位于kernel32.dll中,并不是所有的程序都会装载user32.dll,所以在调用MessageBoxA之前,应该先使用LoadLibrary(“user32.dll”)装载user32.dll。
这里是通用型shellcode编写的步骤:(老师上课的ppt)

难点主要在1-3步,
第一步:定位kernel32.dll位置:

Ppt中的这个图可以更直观的理解这个流程:
如下代码来实现:
1 | int main() |

获得kernel32.dll的基地址:0x76530000
第二步:定位kernel32.dll的导出表
找到了kernel32.dll,由于它也是属于PE文件,那么我们可以根据PE文件的结构特征,定位其导出表,进而定位导出函数列表信息,然后进行解析、遍历搜索,找到我们所需要的API函数。
定位导出表及函数名列表的步骤如下:
(1)从kernel32.dll加载基址算起,偏移0x3c的地方就是其PE头的指针。
PE头偏移0x78的地方存放着指向函数导出表的指针。
(2)获得导出函数偏移地址(RVA)列表、导出函数名列表:
①导出表偏移0x1c处的指针指向存储导出函数偏移地址(RVA)的列表。
②导出表偏移0x20处的指针指向存储导出函数函数名的列表。
同样使用ppt中的流程图: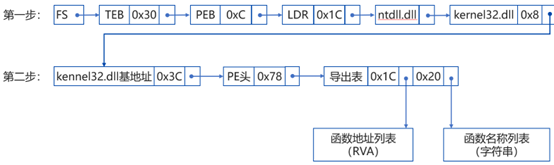
定位kernel32.dll导出表及其导出函数名列表的代码如下:
1 | mov ebp, eax //将kernel32.dll基地址赋值给ebp |
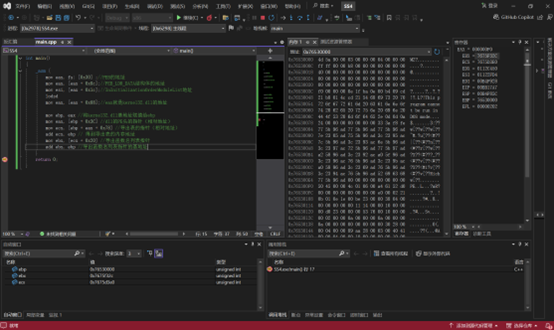
dll的PE头的指针(相对地址):EAX = 000000F0
导出表的指针(相对地址):ECX = 0022D3E0 //导出表
导出表的内存地址:ECX = 7675D3E0
RVA列表:0x0022D408

导出函数名列表指针:EBX = 0022F32C
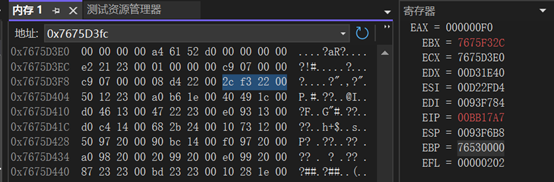
导出函数名列表指针的基地址:EBX = 7675F32C
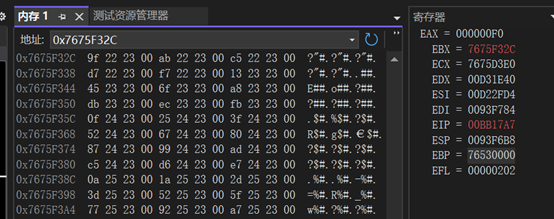
第三步 搜索定位目标函数
至此,可以通过遍历两个函数相关列表,算出所需函数的入口地址:
(1)函数的RVA地址和名字按照顺序存放在上述两个列表中,我们可以在名称列表中定位到所需的函数是第几个,然后在地址列表中找到对应的RVA。
(2)获得RVA后,再加上前边已经得到的动态链接库的加载地址,就获得了所需API此刻在内存中的虚拟地址,这个地址就是最终在ShellCode中调用时需要的地址。
按照这个方法,就可以获得kernel32.dll中的任意函数。
kernel32.dll基地址0x76530000 +函数地址偏移量0x001c9298 =LoadLibraryA函数地址0x766F9298
书中有一张图,和课堂ppt一样,贴过来:
为了让shellcode更加通用,能被大多数缓冲区容纳,总是希望shellcode尽可能短。因此,一般情况下并不会“MessageBoxA”等这么长的字符串去进行直接比较。所以会对所需的API函数名进行hash运算,这样只要比较hash所得的摘要就能判定是不是我们所需的API了。使用的hash算法如示例5-10所示。
压缩函数名的hash算法:
1 |
|
通过上述代码,我们可以获得MessageboxA的hash值。接下来,我们可以在shellcode中通过压栈的方式将这个hash值压入栈中,再通过比较得到动态链接库中的API地址。
完整API函数自搜索代码。首先,基于上述流程找到函数的入口地址;之后,可以编写自己的shellcode,如下面完整代码中的function_call。
完整API函数自搜索代码:
1 |
|
结果如下图所示:

四. 心得体会
自搜索API是为了绕过ASLR保护,除了自搜索API,对于ASLR缺陷和绕过方法,也学习了部分返回地址覆盖法(off by one)。(看到书上有提及)
查资料——在ASLR中,虽然模块加载基地址发生变化,但是各模块的入口点地址的低字节不变,只有高位变化。对于地址0x12345678,其中5678部分是固定的,如果存在缓冲区溢出,可以通过memcpy对后两个字节进行覆盖,可以将其设置为0x12340000~0x1234FFFF中的任意一个值。如果通过strcpy进行覆盖,因为strcpy会复制末尾的结束符0x00,那么可以将0x12345678覆盖为0x12345600,或者0x12340001 ~ 0x123400FF。部分返回地址覆盖,可以使得覆盖后的地址相对于基地址的距离是固定的,可以从基地址附近找可以利用的跳转指令。
理解来看,映像基址随机化只是对加载地址的前两个字节进行了随机化, 后面两个字节没有变化。所以可以通过覆盖后两个字节,在0x0000—0xFFFF的地址空间内寻找跳板,控制EIP,转入payload执行。
实验五:AFL模糊测试工具使用
一. 实验环境
Ubuntu操作系统。
二. 实验目的
下载并编译AFL;
基于给定的示例程序或其他自选目标,学习模糊测试过程。
会分析找到的crash样本。
理解AFL计算代码覆盖率的原理,样本变异的方法。
三. 实验步骤
AFL是一款基于覆盖引导(Coverage-guided)的模糊测试工具,它通过插桩的方式获取程序代码运行轨迹、记录输入样本引起的被测程序已运行代码的覆盖率,从而调整输入样本以提高代码覆盖率、增加发现漏洞的概率。
AFL主要用于C/C++程序的测试,且不论有无被测程序源码均可以测试:有源码时可以对源码进行编译时插桩,无源码时可以借助QEMU的User-Mode模式进行二进制插桩。
其工作流程大致如下:
(1)对待测程序进行插桩(编译时插桩或者二进制插桩),以记录代码覆盖率(code coverage);
(2)选择一些初始输入文件(seed),作为初始测试集加入输入队列(queue);
(3)将队列中的文件按照一定策略进行“突变”(mutate)。在AFL工具中,常用突变方式有按位翻转(bitflip)、整数加/减算术运算(arithmetic)、将特殊内容替换到原文件中(interest)、把自动生成或用户提供的token替换/插入到原文件中(dictionary)、“大破坏”,是前面几种变异的组合(havoc)、“连接”,此阶段会将两个文件拼接起来得到一个新的文件(splice)等;
(4)将突变后的文件输入到被测程序中,如果该文件更新了已运行代码覆盖范围,则将其保留并添加到输入队列中;
(5)上述过程(3)和(4)会一直循环进行,期间触发了被测系统崩溃(crash)的文件会被记录下来。
流程图如下图

1. AFL安装
在Kali 2021系统中,在命令行输入sudo apt-get install afl即可安装。

作用分别为:
- afl-gcc和afl-g++分别对应的是gcc和g++的封装。
- afl-clang和afl-clang++分别对应clang的c和c++编译器封装。
- afl-fuzz****是AFL的主体,用于对目标程序进行模糊测试。
- afl-analyze可以对用例进行分析,看能否发现用例中有意义的字段。
- afl-qemu-trace用于qemu-mode,默认不安装,需要手工执行qemu-mode的编译脚本进行编译。
- afl-plot生成测试任务的状态图。
- afl-tmin和afl-cmin对用例进行简化。
- afl-whatsup用于查看fuzz任务的状态。
- afl-gotcpu用于查看当前CPU 状态。
- afl-showmap用于对单个用例进行执行路径跟踪。
2. AFL进行模糊测试
前文提到不论是否拥有被测程序的源码,AFL都可以进行测试。其区别在于获得代码覆盖率的插桩方式不同:如果拥有被测程序的源码(称为白盒测试),则在程序编译时进行插桩;如果没有被测程序的源码(称为黑盒测试),则在已经编译好的可执行文件上进行二进制插桩。
1)创建本次实验的程序
1 |
|
使用AFL的编译器编译待测程序,可以使模糊测试过程更加高效。
编译命令:afl-gcc -o test test.c
test.c源码编译完成后输出名为test的文件,且编译后test中会有插桩符号,使用下面的命令可以验证这一点。
命令:readelf -s ./test | grep afl,
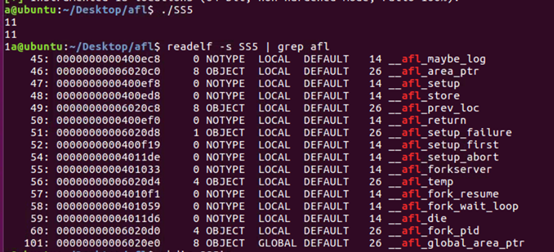
2)创建初始测试用例
首先,使用如下命令创建两个文件夹in和out,分别存储模糊测试过程中使用到的输入和输出文件。
命令:mkdir in out
其次,使用如下命令在输入文件夹(in)中创建一个包含字符串“hello”的文件。注意:这里的字符串“hello”仅为我们提供的初始输入,该初始输入可以为任意字符串,如“hell”“hlo”等均可。
命令:echo hello> SS5in/seed
seed就是我们的测试用例,里面包含初步字符串hello。AFL会通过这个种子进行变异,构造更多的测试用例。

3****)启动模糊测试
运行如下命令,开始启动模糊测试。
命令:afl-fuzz -i in -o out – ./test @@
可能出现:

前文中提到,AFL会监视待测程序的crash并将造成crash的输入记录,因此在进行下一步之前,还需要使用如下命令指示系统将coredumps输出为文件以便AFL监视系统运行状态,而不是将它们发送到特定的崩溃处理程序应用程序。
命令:echo core > /proc/sys/kernel/core_pattern
下面对部分经常用于分析的界面内容进行介绍:
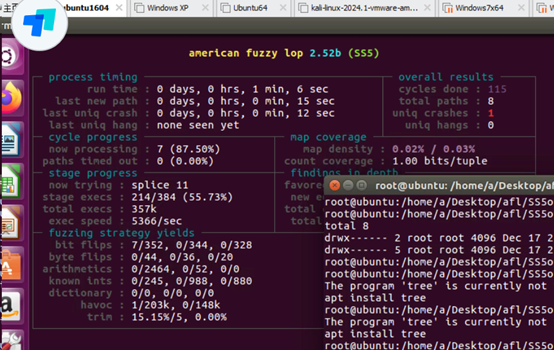
·process timing
这里展示了当前模糊测试程序的运行时间(1min6s)、最近一次发现新执行路径(代码覆盖率增加)的时间(15s)、最近一次崩溃的时间(12s)、最近一次超时的时间(无)。
·overall results
这里包括运行的总周期数(115)、总路径数(8)、崩溃次数(1)、超时次数(0)。
其中,总周期数可以用来作为何时停止模糊测试程序的参考。随着不断地fuzzing,周期数会不断增大,其颜色也会由洋红色,逐步变为黄色、蓝色、绿色(这个看上去像是洋红色)。一般来说,当其变为绿色时,代表可执行的内容已经很少了,继续fuzzing下去也不会有什么新的发现了。此时,我们便可以通过快捷键Ctrl+C结束进程,中止当前的fuzzing。
·stage progress
这里包括在测试过程中使用的突变策略(splice 11)、进度(214/384 55.73%)、目标的执行总次数(357k)、目标的执行速度(5366/sec)。执行速度可以直观地反映当前模糊测试工作跑的快不快,速度越快表示在1秒钟之内执行被测程序的数量越多,如果速度过慢,比如低于500次/秒,那么测试时间就会变得非常漫长。如果发生了这种情况,我们需要调整并优化我们的fuzzing策略,以提高模糊测试效率。
4)分析crash
观察fuzzing结果,如有crash,则定位、分析引起crash的输入。
crash!!!

在out文件夹下的crashes子文件夹里面是在模糊测试过程中引起被测程序crash的样例,hangs里面是产生超时的样例,queue里面是每个不同执行路径的样例。
通常,在得到crash样例后,分析人员可以将这些样例作为输入重新输入到被测程序,以重新触发被测程序异常并跟踪程序运行状态(如代码执行路径),并进一步分析、定位引起程序崩溃的原因或确认存在的漏洞类型。
其中重新输入并尝试触发被测程序异常是排除当前输入仅是偶然引起报错但是无法复现的情况,如有时与被测程序交互需要通过传输网络数据包的形式,可能由于网络波动造成目标程序异常而意外让模糊测试程序认为是当前输入引起的目标程序异常。
如果多次使用相同输入均能复现目标程序的异常,那么可以认为确实是由该输入引起的crash。
与此同时,并不是所有引起crash的地方都是能够被利用的漏洞,是否能够利用还需要通过分析人员的判断。
3.AFL计算代码覆盖率的原理,样本变异的方法
这里有参考文章: [原创]fuzzing原理探究(上):afl,afl++背后的变异算法-二进制漏洞-看雪-安全社区|安全招聘|kanxue.com
Afl主要流程如下:
①在从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage)。
②选择一些输入文件作为初始测试集,加入输入队列(queue)。
③对队列中的文件按一定策略进行“突变”。
④如果变异文件扩展了覆盖范围,则将其保留并添加到队列中。
⑤上述过程循环进行,期间触发 crash 的文件会被记录下来。
其主要功能定义在fuzz_one()函数中
fuzz_one(char** argv):获取测试用例并喂给目标程序

根据优胜者机制按概率跳过

调用trim_case():对当前测试用例进行剪枝,以减少无效数据。
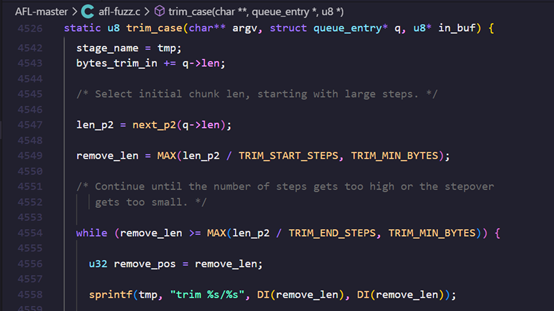
calculate_score():计算测试用例得分。根据执行时间、覆盖率、新路径和深度对测试用例评分,确保高潜力的测试用例在变异过程中获得更多机会。

然后进行变异(如bitflip、arithmetic inc/dec等),变异后调用common_fuzz_stuff处理结果。

save_if_interesting():保存有趣的测试用例。检查执行结果是否有趣,即,调用has_new_bits(virgin_bits)来判断是否产生了新的路径元组,若是则保存或加入队列(add_to_queue)。trace_bits指向由全体进程共享的内存区域,其中包含每次样本执行的覆盖率,其实是之后提到的覆盖次数桶的压缩存储。
AFL 会比较当前输入的执行路径与已有路径信息,判断是否发现了“新路径”。如果覆盖了之前未探索的分支,则认为是“有趣的输入”,并将该输入加入种子池。

如果想要统计覆盖率,就需要用到插桩技术,插桩有三种模式:llvm mode,汇编层面插桩,qemu-mode动态插桩。(前两者是静态,第三者动态)
llvm mode——借助LLVM的Pass来更改中间代码表示IR(Intermediate Representation)(编译器或虚拟机内部用于代表源代码的数据结构或代码),从而在编译过程中实现插桩。
汇编层面插桩——在机器语言的环节:128行,在代码块结束处,调用 __afl_maybe_log__函数,而其为探测点(Probe Points)相关汇编代码

该代码插入点为每个代码块开始部分(不同于函数的入口点),基于开始点,这样记录程序执行此处的次数和路径。
对于分支部分的插桩,因为分支数量往往巨大(em一个小函数的在IDA中的分支块也是很多的),这里使用 inst_ratio_str函数来控制分支插桩比例:

(可以看到llvm和汇编方法中都有相关函数)
Eff_map——记录每个字节是否引起了新路径元组的出现,来评估对整个元组的影响。

Ø 如果 byte 尝试所有改变都没有出现新路径,AFL开发者认为这种字节很有可能只是单纯的非元数据,AFL后续会参考eff_map 进行选择性的跳过。接下来每次变异都会检查eff_map中的对应项 ,如果当前字节对应的项为 0 ,则检查变异以后路径是否有新元组产生,如果是则置为 1。
Ø eff_map会将输入测试用例文件小于128字节的情况(EFF_MIN_LEN),认为每个字节都是有效的,而如果一个测试用例,90%的字节都能触发新路径元组,那么AFL会直接把剩余的10%也认为是有效的。
这种做法改善了变异的方向性,使其能够避免过多的无效变异,从而更加专注于有效的变异。
样本变异的方法
AFL 的样本变异方法是模糊测试的核心,通过随机或特定模式对输入样本进行修改,尝试触发程序的未覆盖路径。以下是 AFL 的主要变异方法:
字节翻转(Bit Flipping):
- 对输入数据的某些比特位进行翻转操作,这里**_ar传入需要进行位翻转操作的字节数组指针,_b**则是要翻转的位置。
- 例如:00000001 → 00000000 或 00000011。
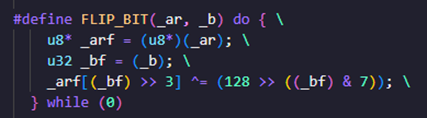
- 这里是一些定义模式:

字节替换(Byte/Substitution Mutation)
整数边界测试(Arithmetic Mutation)
插入和删除(Insertion/Deletion)
字节块复制(Block Duplication)
字节块移位(Block Shuffling)
拼接变异(Splicing Mutation)
特定模式插入(Special Pattern Injection)
- 这里还要提到fuzz过程中,fork操作:
Execve执行需要执行系统终端、系统调用、载入目标文件和库、解析符号地址等操作,如果每次使用execve非常消耗性能。所以afl使用fork服务器机制来减少系统调用次数。Fuzzer和fork的服务器通信、fuzzer和目标进程通过管道通信,目标进程准备好后通知fuzzer开始fork
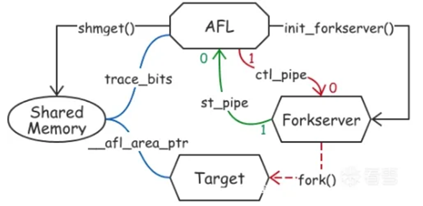
四. 心得体会
在搜索相关资料的过程中,我还发现了一个好玩的——Lcov 对 AFL-Fuzz 进行覆盖率可视化分析
使用 lcov –directory . –capture –output-file test.info 产生 info 文件,再使用genhtml -o results test.info,产生覆盖率可视化文件:


AFL++整合了 AFL 的各类插件,实现兼容性、性能和变异能力的提升,并改进了遗传算法中变异的自定义方案,方便研究人员进行二次开发。
可以研究一下afl++
实验六:渗透测试实验
一. 实验环境
目标主机Windows XP系统。测试主机Linux环境。测试主机中安装Metasploit渗透测试工具和Nessus漏洞扫描工具。
二. 实验目的
\1. 理解渗透测试的定义和主要步骤。
\2. 了解漏洞扫描。
\3. 了解渗透测试。
三. 实验步骤
理解渗透测试的定义和主要步骤。
有一种说法是将渗透测试分为收集、扫描、漏洞利用和后维持攻击四个阶段,而已被安全业界领军企业所采纳的渗透测试执行标准(PTES: Penetration Testing Execution Standard)对渗透测试过程进行了标准化。PTES标准中定义的渗透测试过程环节基本上反映了安全业界的普遍认同,具体包括7个阶段。该标准项目网站的网址为:http://www.pentest-standard.org/。
1. 前期交互阶段
在前期交互(Pre-Engagement Interaction)阶段,渗透测试团队与客户组织进行交互讨论,最重要的是确定渗透测试的范围、目标、限制条件以及服务合同细节。该阶段通常涉及收集客户需求、准备测试计划、定义测试范围与边界、定义业务目标、项目管理与规划等活动。
2. 情报搜集阶段
在目标范围确定之后,将进入情报搜集(Information Gathering)阶段,渗透测试团队可以利用各种信息来源与搜集技术方法,尝试获取更多关于目标组织网络拓扑、系统配置与安全防御措施的信息。
渗透测试者可以使用的情报搜集方法包括公开来源信息查询、Google Hacking、社会工程学、网络踩点、扫描探测、被动监听、服务查点等。而对目标系统的情报探查能力是渗透测试者一项非常重要的技能,情报搜集是否充分在很大程度上决定了渗透测试的成败,因为如果你遗漏关键的情报信息,你将可能在后面的阶段里一无所获。
假设你是在一家安全公司工作的道德渗透测试员,你老板跑到你办公室,递给你一张纸,说”我刚跟那家公司的CEO在电话里聊了聊。他妥我派出最好的员工给他们公司做渗透测试一一这事得靠你了。一会儿法律部会给你发封邮件,确认我们已经得到相应的授权和保障。”然后你点了点头,接下这项任务。老板转身走了,你翻了翻丈件,发现纸上只写了公司的名字, Syngress 。这家公司你从来没听过,手头也没有其他任何信息。怎么办?
信息收集是渗透测试中最重要的一环。在收集目标信息上所花的时间越多,后续阶段的成功率就越高。具有讽刺意味的是,这一步骤恰恰是当前整个渗透测试方提体系中最容易被忽略、最不被重视、最易受人误解的一环。
若想要信息收集工作能够顺利进行,必须先制定策略。几乎各种信息的收集都需要借助互联网的力量。典型的策略应该同时包含主动和被动的信息收集:
(1)主动信息收集:包括与目标系统的直接交互。必须注意的是,在这个过程中,目标可能会记录下我们的IP 地址及活动。
(2)被动信息收集:则利用从网上获取的海量信息。当执行被动信息收集的时候,我们不会直接与目标交互,因此目标也不可能知道或记录我们的活动。
信息收集的技巧很多,除了纯技术性工具及操作外,社会工程学不得不提。不谈社会工程学的话,信息收集是不完整的。许多人甚至认为社会工程学是信息收集最简单、最有效的方怯之一。
社会工程学是攻击“人性”弱点的过程,而这种弱点是每个公司天然固有的。当使用社会工程学的时候,攻击者的目标是找到一个员工,并从他口中撬出本应是保密的信息。
假设你正在针对某家公司进行渗透测试。前期侦察阶段你已经发现这家公司某个销售人员的电子邮箱。你很清楚,销售人员非常有可能对产品问询邮件进行回复。所以用匿名邮箱对他发送邮件,假装对某个产品很感兴趣。
实际上,你对该产品并不关心。发这封邮件的真正目的是希望能够得到该销售人员的回复,这样你就可以分析回复邮件的邮件头。该过程可以使你收集到这家公司内部电子邮件服务器的相关信息。
接下来我们把这个社会工程学案例再往前推一步。假设这个销售人员的名字叫Ben Owned。(这个名字是根据对公司网站的侦察结果以及他回复邮件里的落款了解到的。〉假设在这个案例中,你发出产品问询邮件之后,结果收到一封自动回复的邮件,告诉你Ben Owned “目前正在海外旅游,不在公司”以及“接下来这两周只能通过有限的途径查收邮件”。
最经典的社会工程学的做法是冒充Ben Owned 的身份给目标公司的网络支持人员打电话,要求协助重置密码,因为你人在海外,无法以Web 方式登录邮箱。运气好的话,技术人员会相信你的话,帮你重置密码。如果他们使用相同的密码,你就不但能够登录Ben Owned 的电子邮箱,而且能通过VPN 之类的网络资源进行远程访问,或通过FTP 上传销售数据和客户订单。
社会工程学跟一般的侦察工作一样,都需要花费时间进行钻研。不是所有人都适合当社会工程学攻击者的。想要获得成功,你首先得足够自信、对情况的把握要到位,然后还得灵活多变,随时准备“开溜”。如果是在电话里进行社会工程学攻击,最好是手头备好各种详尽、清楚易辨的信息小抄,以免被问到一些不好回答的细节。
另外一种社会工程学攻击方陆是把优盘或光盘落在目标公司里。优盘需要扔到目标公司内部或附近多个地方,例如停车场、大厅、厕所或员工办公桌等,都是“遗落”的好地方。大部分人出于本性,在捡到优盘或光盘之后,会将其插入电脑或放进光驱,查看里面是什么内容。而这种情况下,优盘和光盘里都预先装载了自执行后门程序,当优盘或光盘放入电脑的时候,就会自动运行。后门程序能够绕过防火墙,并拨号至攻击者的电脑,此时目标暴露无遗,攻击者也因此获得一条进入公司内部的通道。
3. 威胁建模阶段
在搜集到充分的情报信息之后,渗透测试团队的成员们停下敲击键盘,大家聚到一起针对获取的信息进行威胁建模(Threat Modeling)与攻击规划。这是渗透测试过程中非常重要,但很容易被忽视的一个关键点。
大部分情况下,就算是小规模的侦察工作也能收获海量数据。信息收集过程结束之后,对目标应该就有了十分清楚的认识,包括公司组织构架,甚至内部部署的技术。
4. 漏洞分析阶段
在确定出最可行的攻击通道之后,接下来需要考虑该如何取得目标系统的访问控制权,即漏洞分析(Vulnerability Analysis)阶段。
在该阶段,渗透测试者需要综合分析前几个阶段获取并汇总的情报信息,特别是安全漏洞扫描结果、服务查点信息等,通过搜索可获取的渗透代码资源,找出可以实施渗透攻击的攻击点,并在实验环境中进行验证。在该阶段,高水平的渗透测试团队还会针对攻击通道上的一些关键系统与服务进行安全漏洞探测与挖掘,期望找出可被利用的未知安全漏洞,并开发出渗透代码,从而打开攻击通道上的关键路径。
5. 渗透攻击阶段
渗透攻击(Exploitation)是渗透测试过程中最具有魅力的环节。在此环节中,渗透测试团队需要利用他们所找出的目标系统安全漏洞,来真正入侵系统当中,获得访问控制权。
渗透攻击可以利用公开渠道可获取的渗透代码,但一般在实际应用场景中,渗透测试者还需要充分地考虑目标系统特性来定制渗透攻击,并需要挫败目标网络与系统中实施的安全防御措施,才能成功达成渗透目的。在黑盒测试中,渗透测试者还需要考虑对目标系统检测机制的逃逸,从而避免造成目标组织安全响应团队的警觉和发现。
6. 后渗透攻击阶段
后渗透攻击(Post Exploitation)是整个渗透测试过程中最能够体现渗透测试团队创造力与技术能力的环节。前面的环节可以说都是在按部就班地完成非常普遍的目标,而在这个环节中,需要渗透测试团队根据目标组织的业务经营模式、保护资产形式与安全防御计划的不同特点,自主设计出攻击目标,识别关键基础设施,并寻找客户组织最具价值和尝试安全保护的信息和资产,最终达成能够对客户组织造成最重要业务影响的攻击途径。
与渗透攻击阶段的区别在于,后渗透攻击更加重视在渗透进去目标之后的进一步的攻击行为。后渗透攻击主要支持在渗透攻击取得目标系统远程控制权之后,在受控系统中进行各式各样的后渗透攻击动作,比如获取敏感信息、进一步拓展、实施跳板攻击等。
7. 报告阶段
渗透测试过程最终向客户组织提交,取得认可并成功获得合同付款的就是一份渗透测试报告(Reporting)。这份报告凝聚了之前所有阶段之中渗透测试团队所获取的关键情报信息、探测和发掘出的系统安全漏洞、成功渗透攻击的过程,以及造成业务影响后果的攻击途径,同时还要站在防御者的角度上,帮助他们分析安全防御体系中的薄弱环节、存在的问题,以及修补与升级技术方案。
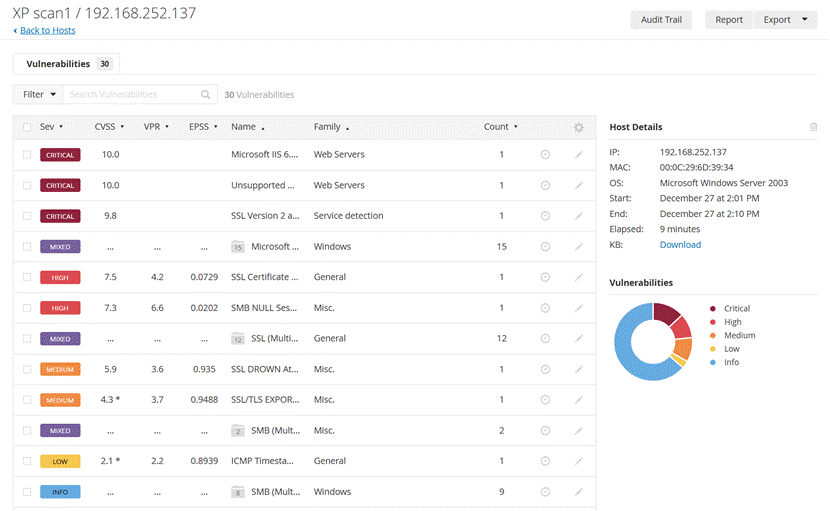
第一步:漏洞扫描
使用nmap发现存活主机:
端口扫描:

指纹探测:
是win XP
在进行渗透测试之前,需要进行漏洞扫描。 Nessus提供完整的电脑漏洞扫描服务,并随时更新其漏洞数据库。Nessus可同时在本机或远端上遥控,进行系统的漏洞分析扫描。

第二步:启动Metasploit渗透攻击
Metasploit是一个开源的渗透测试框架软 件,也是一个逐步发展成熟的漏洞研究与渗透代码开发平台,支持整个渗透测试过程的安全技术集成开发与应用环境。
点入第四个混合漏洞
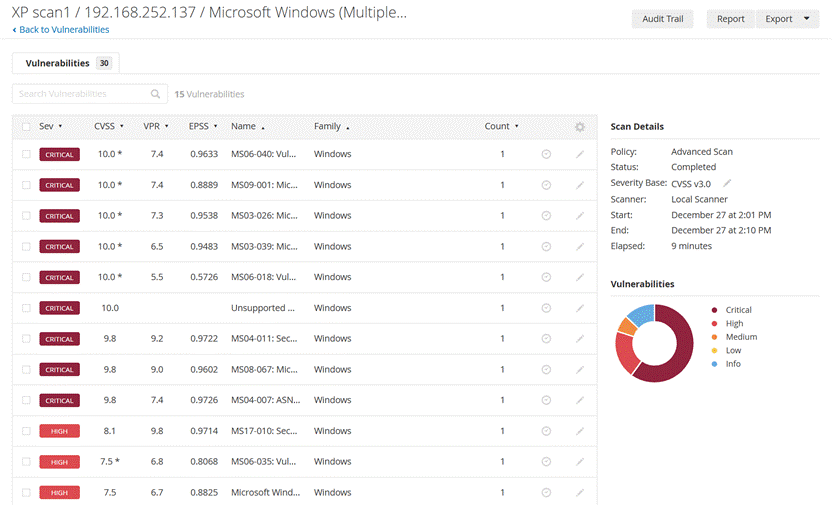
MS06-040
Vulnerability in Server Service Could Allow Remote Code Execution :

在msf中找找

装载并配置:

没打通:

查了一下原因,在尝试匿名SMB登录时,被拒绝了
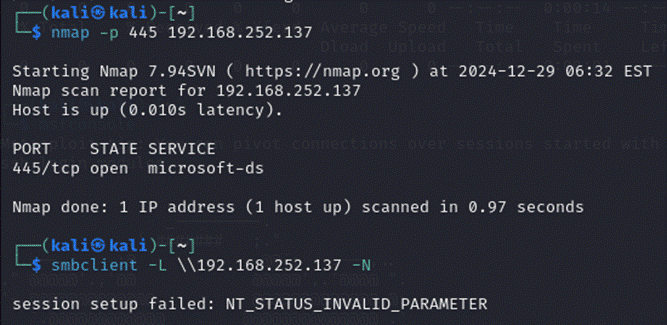
更换其他的攻击模块:
MS03_026


攻击:

攻击成功:

四. 心得体会
了解了一下ms03_026这个漏洞:
CVE-2003-0352漏洞,该漏洞由lds-pl.net研究组于2003年发现,影响包括Windows XP、Windows NT、Windows 2003等在内的多个微软操作系统版本。
漏洞源于微软RPC框架在处理TCP/IP信息交换过程中的畸形消息时未能正确处理,导致缓冲区溢出。
攻击目标:使用DCOM接口的Windows RPC 服务器
微软修改dcerpc框架后形成自己的RPC框架来处理进程间的通信。微软的RPC框架在处理TCP/IP信息交换过程中存在的畸形消息时,未正确处理,导致缓冲区溢出漏洞;此漏洞影响使用RPC框架的DCOM接口,DCOM接口用来处理客户端机器发送给服务器的DCOM对象**请求,如UNC路径
想按照上课讲的看看我队友的站:h@ck
被动信息收集:
现在已知域名:https://wz0beu.cn/
搜索引擎:

Site指令:
IP地址查询:
1 | C:\Users\lenovo>ping www.wz0beu.cn |
CDN(Content Delivery Network,即内容分发网络)基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问网站时,利用全局负载技术将用户的访问指向距离最近的工作正常的缓存服务器上,由缓存服务器直接响应用户请求。所以上面得到的IP不是真实web服务器的IP地址
1 | C:\Users\lenovo>ping wz0beu.cn |
去掉www,可以得到真实IP
whois信息收集:
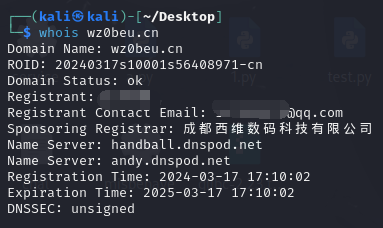
当然这个也能搜:wz0beu.cn的Whois信息 - 站长工具
DNS信息收集:

主动信息收集:
端口扫描:
指纹探测:
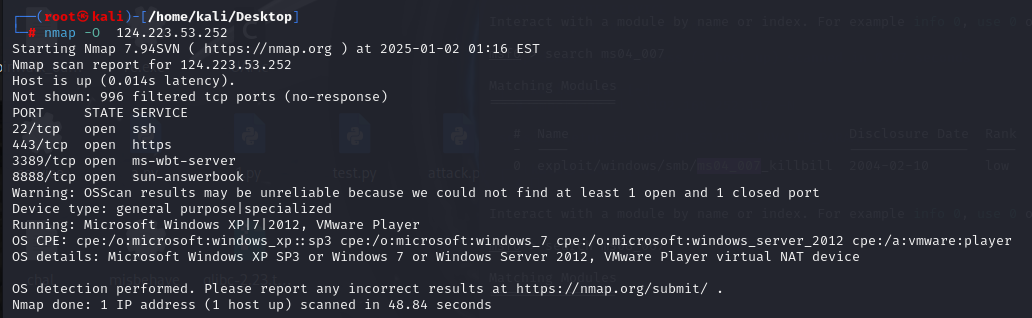
Microsoft Windows XP SP3 or Windows 7 or Windows Server 2012, VMware Player virtual NAT device
web指纹探测:
这里是一些常见的错误页面:
Apache:
IIS:

Nginx

xp:


